Neural Networks for object detection and classification
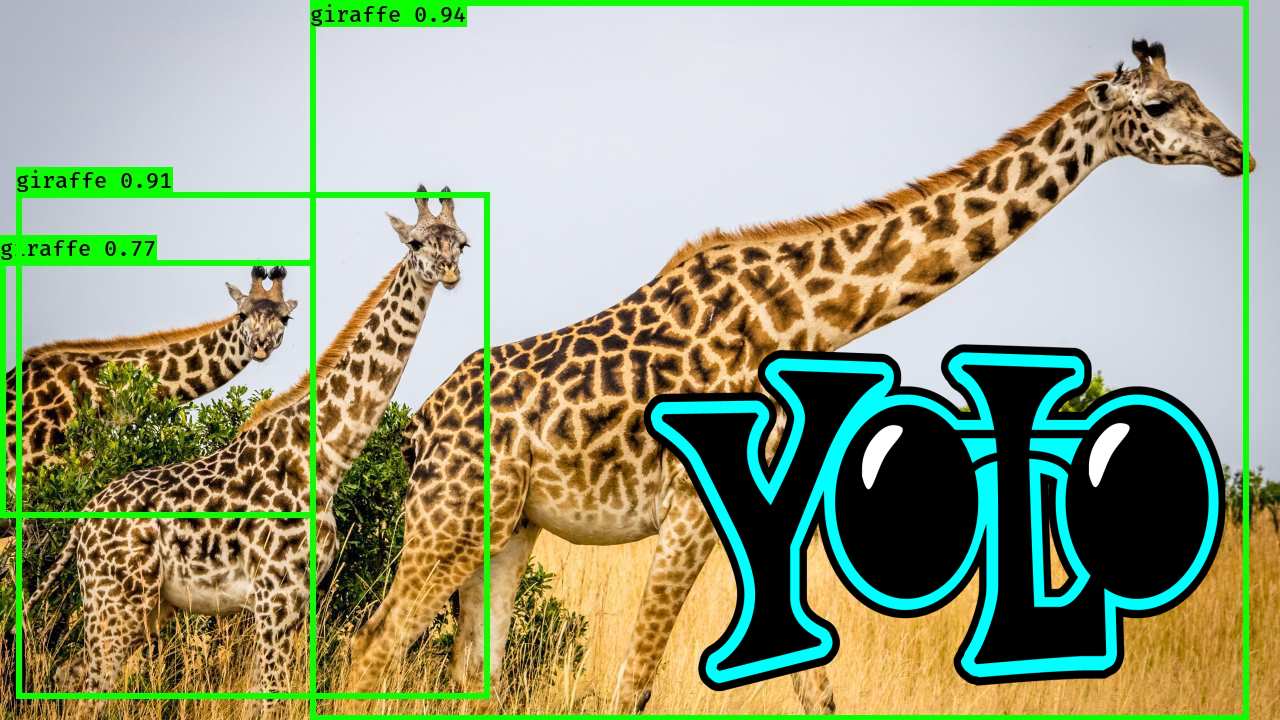
Identify objects in your images with computer vision algorithm YOLO.
Introduction
You only look once (YOLO, empahsis on once) is an object detection system using Convolutional Neural Networks (CNN) targeted for real-time processing of camera feeds of all sorts. YOLO is faster than previous algorithm since it does two steps in one. The algorithm divides the image into tiles (e.g. 13x13) and runs the inference for object bounding boxes and object classification on all image tiles simultaneously through the CNN. For example, self-driving cars heavily rely on reliable and fast algorithms, since they need to identify other cars on the street with a camera mounted in the grille.
YOLOv2 can be run repeatedly over the input of a camera (30 frames/s) but can make inferences at a speed of 40 times/s! A total of 80 classes are detected in YOLOv2. Only recently YOLO9000 was trained using transfer learning from ImageNet to detect >9000 classes!
Prediction on stock photos: 
Source: Photos from https://unsplash.com/, with own inferences.
As you see in the video above, YOLOv2 is not perfect at all yet. Many objects were misclassified, or were not seen because they were too small, or were no class in the first place.
But how does YOLOv2 work in detail?
How it works
1. Intuition
The input image is divided into nH x nW grid (for example 13×13 in the architectureal diagram). Each grid cell predicts a fixed number of anchor boxes and confidence scores for those anchor boxes. Each anchor box consists of 5 predictions bx, by, bw, bh and pc (bx,by coordinates of box center; bw, bh lengths of box dimensions, pc confidence) added to the number of classes. The confidence pc here is only for binary classification that those bounding box contains an object or not. With m being the number of input images, the encoded output vector looks the following: (m, nH, nW, anchors, classes), in the case of YOLOv2 that is (m, 13, 13, 5, 85) tensor.

Source: Modified after https://unsplash.com/
2. Network Design
The architecture of the YOLOv2 CNN is typical for most CNNs, where the height and width of the image shrinks through un-padded convolutions, but get deeper through increasing filers:
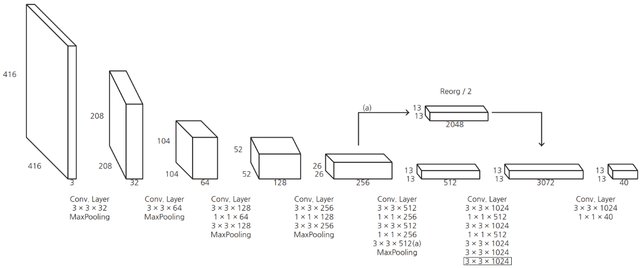
Source: Seong et al., 2019
The image is resized to 416×416 pixels for training and run through numerous convolutional layers of which many are 1x1 in size to reduce the number of parameters (computational complexity). YOLOv2 removed the 2 fully connected layers and uses anchor boxes to predict bounding boxes.
3. Non-Max Suppression
In inference phase, the YOLOv2 algorithm can output multiple bounding boxes for the same object in adjacent tiles and non-max suppression is a technique to resolve it. What non-max suppression do is to keep only the bounding box having maximum confidence score among all boxes that have same classification and have an IoU value (Intersect over Union) >0.5. All boxes that do not meet criteria are eliminated, only the remaining bounding boxes will be displayed.

Source: Modified after https://unsplash.com/
Outlook
If you wanted to run YOLO, that will not be that easy, since it was originally implemented in C language with a neural network framework called Darknet. Running it in Python and Keras does not require you to do the conversion work yourself. Multiple projects have already done that conversion work for you: for example Allan Zelener - YAD2K: Yet Another Darknet 2 Keras. However, I encourage you to try out the deeplearning.ai implementation. Download the contents of this folder. Copy your images for inference into the folder “images”. Make sure all images are exactly 1280x720 resolution. Read through the notebook and runn all cells and look into the “out” folder what your computer’s vision is.
YOLO was trained on for some epochs on the pre-trained ImageNet using high-power GPUs. Hence, it is not recommendable to train it yourself. Be advised to download the pre-trained values to make inferences only! The algorithm is continuously optimized by various computer scientists. For example the new iteration YOLO9000, which vastly inceased the number of classes. Have a read of the links given below on how the different versions of YOLO stack up against other computer vision neural networks.
Prediction on video feed: 
Source: Sik-Ho Tsang 2018
Further Reading
Jupyter Notebook deeplearning.ai
Jonathan Hui 2018: Real-time Object Detection with YOLO, YOLOv2 and now YOLOv3
Sik-Ho Tsang 2018 Review: YOLOv2 & YOLO9000 — You Only Look Once (Object Detection)