My Machine Learning Model Is Perfect

Reasons that make ML experts look at your code twice.
Code that needs refactoring
Strange and hard-to-read code is a common reason to elicit refactoring (rewriting). Think of unstructured Spaghetti Code™ without a lot of documentation – or the opposite – too much documentation that you can’t see the forest for the trees anymore. These kind of code issues are called “code smell”. A term that has been widely adopted after 1999 when the book “Refactoring: Improving the Design of Existing Code” by Martin Fowler was published. Its essence, refactoring is applying a series of small behavior-preserving transformations with the cumulative effect of “reducing the risk of introducing errors”.
Some smells are easy to spot, some subtler and more insidious than others. While these problems and signs may not be detrimental by themselves, they warrant a closer look. You may have seen some of them before:
- Unnecessary complexity (a.k.a. showing off).
- Functions with too many arguments, indicating “God functions” without partitioning into helper-functions.
- Runaway function length across the screen making it hard to read.
- Excessive commenting making it hard to distinguish code from non-code.
- Duplicated code - That’s where the principle Don’t Repeat Yourself (DRY) comes from.
Have a look at the full list of code smells and their description on Wikipedia and what Anupam Chugh discusses in his TowardsDataScience post “5 Python Code Smells You Should Be Wary Of”.
Breakout: Who has the smelliest code?
At the time of writing this, Google Search users from Washington state were the most interested in code smells or at least ranking very highly. Check now on Google Trends. Is their code the smelliest of them all? Interest likely correlates with the amount of coders in a state and inevitably there is problematic code among.

Photo by @claybanks on Unsplash
What does Machine Learning smell like?
Almost all Machine Learning entails someone writing code. This means the known problems or smells may be emanating from the codebase - regardless if we have written it or someone else put it into a black box for us to call. Machine Learning models are traditional functions but are mathematically adhering to different paradigms: a function that relates sample value X to some target value y. While all the functions of a comprehensive ML/DL library such as PyTorch, TensorFlow, and Scikit-learn are hopefully optimized and free of code smells under the hood, a project involves more than just a single algorithm that’s invoked in a single function. The workflow of invoking the library’s functions bespoke to our project’s needs is a “metamodel” with design complexities of its own.
So what are the “ML smells” that might alert us to deeper problems in our prediction tools?
Dr. Matt Hall recently asked the following question on Twitter and in the geological machine learning community Software Underground he co-founded:
🐽 ML smell is probably not a thing, but maybe it should be. What are the superficial signs of potentially deeper problems in a #machinelearning project?— Matt Hall (@kwinkunks) October 7, 2020
Matt crowdsourced some excellent responses:
Black-box services such as AutoML.
Counterintuitive model weights -> known effects have low feature importance. (Reece Hopkins, Anchorage)
Unreproducible, non-deterministic code -> not setting random seeds. (Reece Hopkins, Anchorage)
No train–val–test split description/justification. Leakage between training and blind data is easy to introduce with random splits in spatially correlated data. (Justin Gosses, Houston)
No evaluation metric discussion -> how it was selected or designed (Dan Buscombe, Flagstaff)
No ground truth discussion and how the target labels relate to it. (Justin Gosses, Houston)
Excessive hyperparameter precision -> might suggest over-tuning. (Chris Dinneen, Perth)
Precision–recall trade-off not considered -> especially in a binary classification task. (Dan Buscombe, FLagstaff)
Strong class imbalance and no explicit mention of how it was handled. (Dan Buscombe, Flagstaff)
Skewed feature importance on one or two features might suggest feature leakage. (John Ramey, Austin)
Making excuses -> “we need more data”, “the labels are bad”, etc. (Hallgrim Ludvigsen, Stavanger)
Time spend cleaning data too short -> Less than 80-90% of the effort spent on preparing the data. (Michael Pyrcz, Austin)
Very high accuracy, e.g., 0.99 for a complex model on a novel task. (Ari Hartikainen, Helsinki and Lukas Mosser, Athens). In most real-world scenarios accuracy near 0.7 is excellent, and anything >0.8 indicates something unusual going on.
That’s a long list, but there are most likely more.
Most likely we have our own biases and tendencies to produce some smell because we were not aware, did not know any better, or had no other choice. This is where peer review provides a second (or third, or fourth…) pair of eyes is critical and all smells get cleaned up.
What do you think?
How perfect is your ML code and what kind of surface phenomena have you seen that may indicate deeper-rooted problems in ML projects?
Maybe it is time for someone to officially coin a new term called “ML Smell”…..
Thank-you to Matt Hall whose question inspired me to write this up! Don’t build from scratch! You want: This is going to easy, because this is a LaTeX template that has your needs covered. You are going to build the documents from source code by yourself. The template code is an evolution of the “Friggeri CV”, which was later substantially enriched in features by Jesper Dramsch in his repo “latex-cv-boosted”. If this sounds compelling, then head over to the GitHub repository to learn more. Not even that…. good. I love watching science-fiction films. In fact, as Student Union President during my Master’s I used to organize geology-related films about which whe had recently rearned in lectures. At least geology-related science-fiction films are usually so bad that they are good again: The Core, 2012, San Andreas, Dante’s Peak etc. Just for reference, in The Core the main characters used a giant drill through magma in the earth to jump-start the metal core’s rotation…. cough. Whenever I watch a sci-fi movie from a field I am less familiar with, I find it exciting to learn if the plot was at least marginally in accordance with the laws of nature. Honestly, there exits the full breadth of science-accuracy delivered by Hollywood from almost-documentary to completely bogus fluff. In my opinion, the Goldilocks situation is met if they achieve to combine excitement and awe with a reasonable adherence to laws of nature, e.g. “Jurassic Park”. For the past New Years days I made it an occasion to re-watch “Interstellar” – a gem in the astrophysics realm I had already seen in the theater when it was released. Most of the plot seemed relatively plausible to me. But I am not an astrophysicist, and what do I know about the details of General Relativity? So let’s find out what the the professor of astrophysics at North Carolina State University, Dr. Katie Mack, has to say in her review for the World Science Festival. Cinema Peer Review: Astrophysicist Katie Mack Reviews ‘Interstellar’ Well, returning from that read, I’m glad that Matthew McConaughey is still with us and did not have to be spaghettified. Dr. Mack brought up numerous pain points that I did not realize they were there. Ach, you were the chosen one, Interstellar. Scientific American: In “2012” neutrinos melt Earth’s core, and other disasters American Geophysical Union: Cinema Peer Review: Astrophysicist Katie Mack Reviews “Interstellar” GeoTimes: Watching The Core: A movie review Arizona Geological Survey: Review: San Andreas – The Movie What I read in 2020. Whenever I am looking for a new book to read, I really enjoy looking at lists of books other people read. Since I started reading more again this year (covid19…), I thought it would be a good idea to write down some thoughts on the individual books. I ended up picking up a new book almost every month. In the following, I describe the more interesting ones of them. Reinforcement learning is a subarea of Machine Learning with some essential differences to (un)supervised learning. The fundamental idea is that we want to train an agent that learns how to perform tasks in a dynamic environment. In contrast to supervised learning, the feedback given to the agent is delayed and does not tell it what the best action would have been. Because reinforcement learning is a bit of a niche area in Machine Learning, I never really got into it when I was new to the field. Still, the fundamental idea sounded incredibly interesting to me, so in the holidays after the winter semester I decided to work through this book. This was just in time to read the reworked second edition. The book was written by Sutton and Barto who are renowned experts in the field and came up with many of the most important ideas themselves. While the book does contain a large amount of math, it is still very accessible because everything is explained up from the ground up. Mentally processing the book was a lot of fun and I got a lot of inspiration for the future. Reinforcement learning is the key element in the AWS Deep Racer and I still marvel at the way it builds up the entire framework step by step. A Dance with Dragons is the fifth book from the A Song of Ice and Fire series that Game of Thrones is based on. After I read the first four book in 2015–2017, I was planning to read the other last book this year just so that I would be done when the sixth book was going to come out. Unfortunately, that book got delayed further and further and is not even out by now. All in all, I really enjoyed the book and its excruiciating details that greatly tops the TV series. Remembering all the >100 characters per book is not that easy, as Martin loves to explain backstory that does not really pertain to the plot. The writing style is neihter too dramatic nor withdrawn and I enjoy how each chapter is told from the point of view of a different character. However, sometimes story lines in some threads is not touched in a long time and comes up perhaps once in a book. Then it sometimes is better to get a reminder what was going in that corner of the world a couple hundred of pages ago. The Master Algorithm is a pop-scientific book about machine learning. It gives a nice overview of fundamental concepts and talks about the history of the field. The book is written for a general audience and does not assume prior knowledge. Domingos uses a lot of analogies, some of which were great, while some did not hit the nail on the head, I think. However, it is evident that he put in a lot of effort into trying to explain machine learning to people that are not from the field. The fundamental idea behind the book is that there are five different schools of thought in machine learning. These are the evolutionist, Bayesian, analogist, symbolist, and the currently dominating connectionist approach. Domingos argues that if we want to create a master algorithm that matches the learning power of our brain, ideas from all these tribes ought to be combined. The first part of the book introduces the five tribes and their main ideas. This was the strongest part of the book and I will probably go through this again at some point. The second part attempts to describe how they could be combined. This feels a bit forced and felt fairly abstract, since it is not entirely clarified how this should work. The book gives a good overview of subcultures and interests and tries to explain why some people feel drawn to them and coding in general. Thompson introduces the reader to coder culture and highlights a few case-study personalities he interviewed. He starts out with early history, such as computation at university servers, and later programming at home. Large part of the book is analyses of students in Computer Science programs and societal groups dominating the profession. In general, the book gives a good overview of subcultures and interests and tries to explain why some people feel drawn to coding in general. But it is never too technical to scare off people not familiar with the subject matter, I felt. The Sense of Style is a style guide that tries to explain how to write more elegantly and effectively. Now, there is no lack for how to write effectively, technical, scientifc, fast etc. However, Pinker’s work, Prof at Harvard U. Psychology Departmet, was smart enough to keep me reading – finding it even enjoyabl Partly, this is definitely because it is written by a highly eloquent author, which helps building your own style. The book addresses not only stylistic choices but also dives into more psychological aspects. One of these points that I really internalized is what the author calls the curse of knowledge. By having a deep understanding of a topic, it becomes incredibly hard to explain it in a good way to people without much prior knowledge. This is due to the fact that we forget the difficulties we had when first learning about the topic ourselves. Now it all seems so simple and it’s easy to fall into the trap of thinking that certain parts are also obvious to other people. Machine Learning’s ‘Hello World V2’ Dataset with Clothing. In 2017, Zalando Research published a dataset, which is very similar to the well known “Hello World” of Computer Vision: the MNIST database of handwritten digits. The dataset is designed for machine learning classification tasks and contains in total 60,000 training and 10,000 test images (gray scale) with each 28x28 pixel. Each training and test case is associated with one of ten labels (0–9). Up till here Zalando’s dataset is basically the same as the original handwritten digits data. However, instead of having images of the digits 0–9, Zalando’s data contains (not unsurprisingly) images with 10 different fashion products. Consequently, the dataset is called Fashion-MNIST dataset, which can be downloaded from GitHub or Kaggle. A few examples are shown in the following image, where each row contains one fashion item. The 10 different class labels are: According to the authors, the Fashion-MNIST data is intended to be a direct drop-in replacement for the old MNIST handwritten digits data, since there were several issues with the handwritten digits. For example, it was possible to correctly distinguish between several digits, by simply looking at a few pixels. Even with linear classifiers it was possible to achieve high classification accuracy. The Fashion-MNIST data promises to be more diverse so that machine learning (ML) algorithms have to learn more advanced features in order to be able to separate the individual classes reliably. Since the structure of the files in the Fashion-MNIST data is the same as for the old MNIST data, it is easy to load the new data with the older code. Using Additionally, I added a function (quick & dirty code) to visualize a sample of training images. The function basically samples the training data and shows random images in a squared grid. If desired, the images are arranged in a way that each row contains only samples from one class: For example, with Overall, the Fashion-MNIST dataset is an interesting test-bed for beginners in machine learning to apply different already existing algorithms. More advanced data scientists could use this data for a fast first evaluation of new approaches. However, this dataset is too simple to deliver reliable/comparable performance measures for new machine learning algorithms. Although I did not test it yet myself, I expect that simple convolutional neural networks would achieve an accuracy of around 90% on the Fashion-MNIST test data. More advanced neural networks can probably achieve an accuracy higher than 95%. For comparison, according to Zalando Research, the human performance is about 84%. Can you recognize some fashion items in the following matrix (although they are that tiny)? Our poor ML algorithms sometimes have to do this millions of times per day. Basic prinicples you need to know. In the previous articles about Machine Learning (ML) I touched advanced topics such as Computer Vision, Tensorflow Cats Vs Dogs I, Chat Bots, and many more. However, I never got into the nitty gritty details how Data Scientists and Machine Learning Enginneers deal with the model training and the maths behind the curtain. Let’s get to it now: Often it is impossible or impractical to compute certain values exactly to the last digit. This might be because it would take too long computationally or because we do not have not enough information. Instead, these values can be Estimation theory is useful to understand different versions of gradient descent. Typically, the gradient is only estimated using methods like (1) mini-batch or (2) stochastic gradient descent. Here, estimation theory can be used to explain the ideas behind these techniques. An estimator is a function (provided by your ML library) that estimates a value based on other observations. This process can involve randomness. For example, because the function itself is random or because there is random noise in the observations it uses. One measure for the quality of an estimator \(\tilde{X}\) (sometimes called \(\hat{X}\)) is its bias or how far off its estimate is on average from the true value \(X\): \[\begin{aligned} \mathrm{bias} ( \tilde{X} ) = \mathrm{E} \lbrack \tilde{X} \rbrack − X \end{aligned}\] where the expected value is over the randomness involved in \(\tilde{X}\). If the bias of an estimator is \(0\), it is called an unbiased estimator. This is generally a desirable property to have because it means that the estimator is correct on average. If one samples for long enough from the estimator, the average converges to the true value \(X\). This is due to the law of large numbers - but in reality we rarely have this luxury, unless we can horde immense amounts of data. Theorem: If \(k\) estimators all produce unbiased estimates \(\tilde{X}_1, \dots, \tilde{X}_k\) of \(X\), then any weighted average of them is also an unbiased estimator. The full estimate is given by \[\begin{aligned} \tilde{X} = w_1 * \tilde{X} _1 + \dots + w_k * \tilde{X} _k \end{aligned}\] where the sum of weights \(\textstyle\sum_{i=1}^k w_i = 1\) needs to be normalized. Proof: The unbiasedness is due to the linearity of expectation: \[\begin{aligned} \mathrm{E} \lbrack \tilde{X} \rbrack &= \mathrm{E} \lbrack w_1 * \tilde{X} _1 + \dots + w_k * \tilde{X} _k \rbrack \\[2em] &= w_1 * \mathrm{E} \lbrack \tilde{X} \rbrack + \dots + w_k * \mathrm{E} \lbrack \tilde{X} _k \rbrack \\[2em] &= w_1 * X + \dots + w_k * X \\[2em] &= X \\[2em] \end{aligned}\] This theorem about unbiased estimators is going to prove to be useful later. However, even if we have an unbiased estimator, its individual estimates can still be far off from the true value. To quantify how consistently an estimator is close to the true value, another statistic is required. Commonly, the variance of the estimator is considered here: \[\begin{aligned} \mathrm{Var} \lbrack \tilde{X} \rbrack = \mathrm{E} \lbrack ( \tilde{X} _k - X ) ^2 \rbrack \end{aligned}\] It is defined as the mean squared distance between the estimate and the value to be estimated. Many different things can be analyzed using estimators. For example, statistical and ML models can be seen as estimators. They use observations (samples, data…) to make predictions. These predictions are generally not perfect because randomness is involved and only a limited amount of information is available. Thus, it makes sense to analyze statistical models in terms of bias and variance. A central problem when building models is balancing underfitting and overfitting. If the training data is just memorized, the model does not generalize well to new data. This is a case of overfitting. The opposite issue, only barely matching the pattern in the training data, is called underfitting. This problem is also known as the bias-variance tradeoff: If the model has a high bias, its predictions are off, which corresponds to underfitting. If overfitting occurred, i.e., the data is learned too well, the estimates have a high variance. By resampling the data that the model was built on, totally different estimates are generated. This is because the model is now based on different random noise. Generally, it is not possible to perfectly optimize both, bias and variance, so they need to be balanced here. In other words, we accept a certain bias of the model to keep its variance low. A good tradeoff between the two needs to be achieved. In supervised machine learning, we compare our model’s predictions to the true labels. This is done using a loss function. If a set of data points \(x_1, \dots , x_n\) and labels \(y_1, \dots , y_n\) is given, then the full loss is defined by \[\begin{aligned} L = \frac{1}{n} \sum_{i=1}^n \mathrm{loss} (f(x_i),y_i) \end{aligned}\] where \(\mathrm{loss}\) is a function that compares a prediction \(p\) to the correct answer \(y\). One choice for the loss function might be the quadratic error (or Mean Absolute Error, Mean Squared Error, Median Absolute Error… etc.): \[\begin{aligned} \mathrm{loss} (p,y) = (p-y)^2 \end{aligned}\] Gradient descent optimizes the parameters used in \(f\) by computing the gradient of the loss with respect to these parameters. This gradient is then used to continually improve the parameters step by step during the descent. To compute the gradient \(ΔL\) of the loss, we can make use of the linearity of the gradient operator: \[\begin{aligned} ΔL &= Δ\frac{1}{n} \sum_{i=1}^n \mathrm{loss}(f(x_i),y_i) \\[2em] &= \frac{1}{n} \sum_{i=1}^n Δ \mathrm{loss}(f(x_i),y_i) \end{aligned}\] The method that uses the gradient given above is sometimes referred to as full-batch gradient descent because it fully uses the available training data in each iteration. Sometimes it also only called “Batch Gradient Descent” but that can be imprecise and confusing. In many cases, the full set of samples \(n\) is a very large value and computing the full update \(ΔL\) is expensive. Since computing the gradient is by far the most expensive part of gradient descent, it makes sense to try to make this more efficient. Computing the gradient as shown above is especially inefficient if there is duplicated training data. If the training set consists of 10 copies of a different dataset, then the evaluation of the formula above is unnecessarily expensive. Every required calculation is repeated 10 times. While this is an extreme example, it does happen in practice that much of the training data is similar. To save time, it often makes sense to only use a part of the data to estimate the gradient. In stochastic gradient descent (SGD), one single data point \(x\) and label \(y\) are sampled uniformly from the training set. This makes it the opposite extreme of Full-Batch Gradient Descent. The true gradient \(ΔL\) is then estimated using only this one data point and label: \[\begin{aligned} Δ\tilde{L} = Δ \mathrm{loss} (f(x),y) \end{aligned}\] It is easy to see that \(Δ\tilde{L}\) is an unbiased estimator of \(ΔL\): \[\begin{aligned} \mathrm{E} \lbrack Δ \tilde{L} \rbrack &= \sum_{i=1}^n Δ \mathrm{loss} (f(x_i),y_i) \\[2em] &= \frac{1}{n} Δ \sum_{i=1}^n \mathrm{loss} (f(x_i),y_i) \\[2em] &= ΔL \end{aligned}\] The computations for SGD can be performed very quickly but still give us an unbiased estimate of the true gradient. This property is the reason why optima can be found using this algorithm. While individual estimates are off, the randomness averages out over iterations and the parameters still move in a sensible direction overall. Since iterations are much cheaper, many more of them can be performed and this is a major improvement to computing the full gradient. These individual SGD estimates can have a large variance however, leading to noisy and jumpy gradients that show as zig-zaggy training histories. A further improvement over this method is mini-batch gradient descent. Instead of just taking one sample, we sample a small batch of \(k\) samples \(1 < k \ll n\), which makes it a compromise between Full-Batch Gradient Descent and Stochastic Gradient Descent. The estimated gradient is an average of all \(k\) single estimates. Each of these individual estimators is unbiased since SGD itself is unbiased. As shown in the theorem earlier, a weighted combination of them still remains an unbiased estimator. Thus, mini-batch gradient descent is also an unbiased way of computing gradient estimates. Mini-batch gradient descent does have much less variance, however, because more data is used to compute the estimate. This makes the optimization process less noisy and smoother compared to using SGD. Most gradient computations can be formulated using linear algebra operations. These calculations can be vectorized (parallelized very well on grphics cards that with CUDA (Don’t wait for hours). So with appropriate add-in boards for your computer there is no significant performance penalty for using Mini-Batch Gradient Descent to compute the model. Thus, Mini-Batch Gradient Descent is the preferred method that leads to a more stable optimization process. If you liked this mathematical representation of the formulas in this article and would like to adopt it, check out https://katex.org/, a LaTeX implementation for the web. It is implemented via What trade-offs will you have to make? This year has brought many changes to the workplace, academia, and how we spend our spare time. Many events that would be held in person are now online. This has its perks but also challenges. I decided to sign up for the 2020 TAMU Datathon at Texas A&M, since I had a great experience last year. And yes, I was accepted again, knowing that the participant pool was doubled since there were no more physical space constraints how many people could be crammed into a hall safely. So far, so 2019 (read post here). Everything started very similary as the 2019 event: Apply online, sign up for the Slack channel, if possible find team mates in the days prior to the event, spend 24 hours working from Saturday Noon to Sunday Noon. A few days in advance I found two other participants to form a team. The challenges were not announced until the actual start of the event, so it was difficult to recruit members for skills and I just had to go by who was interested to forge a small group. Three is ideal, I think. The main divergence comes next: You don’t travel to the event location, but simply get all your information from the hackathon website, the Slack channel, video streams (ceremonies), and perhaps participate in some video calls (e.g., instructional courses by the organizers). I want to recount the perks and challenges of this experience, and what I took away from it. Looking at the pros and cons, it may seem that the arguments are more or less balanced. But think again, if you had the choice between in-person and online, then why didn’t we have so many online hackathons until now? Working remotely in a team can be a big challenge if no rules are established in advance. My impression was that the startup, i.e., search for data, collection, and assessment was the most collaborative part of our project and from then on quieted down. I really think it is important to report frequently what everyone is working on, and help each other out with problems to find solutions or ways to refactor. For example, it may be a good idea to have regular (1-2 hour) Slack voice calls with the team to share results, needs, and plans. In 2019, my team sat together and all worked in their Jupyter notebooks - constantly explaining what each one was doing. This year I wanted to try out Google Colab, since I thought this would improve colaboration and have everyone add to the same file where all progress was instantly visible. But this turned out to be a major pain point. I remember having had several unpleasant situations where cell contents were deleted during lagging syncronization and having to re-write large parts of notebooks. Establishing a Git repository may be the more reliable way to go until synchronization issues are eliminated from Colab. I assume that hackathons will likely go back to in-person events as soon permissible again. But I also hope that they may become hybrid events, if the double organization of online streaming and local people is not too much to lift. It would allow for remote participants to hack away from the other end of the country and likely increase popularity and participation rates even further. Teams are required to adapt their communication frequency and style for this new mode of colaboration to get get equally good results as in-person. What do you think? Did you participate in any hackathon and what are your experiences? Explore AirBnB listings - what options drive the price? I have been to Berlin for various occasions and will likely visit there again. My stays are a mix of hotel rooms, hostels, and private rooms with AirBnB. Returning there, I would like to optimize my AirBnB booking, and for that reason I am running an analysis on the current listings. The most touristy attractions, including government institutions, are located in ‘Mitte’ central district. My hypothesis is that listings are going to be most expensive in the center. Perhaps you can learn something from this, too and optimize your spending. Caution: these findings are for Berlin specifically and may not carry over to other cities. Find optimal AirBnB website settings that lead to smart booking decisions. What types of listings cost more? Where are prices lowest/highest? etc. A. How are the prices distributed? B. Breakdown of listings by room type. C. What is the median price of a listing by district and room type. D. What is the average difference in a listing price between superhost and non-superhost status for each room type and district? E. Which website options influence the price? (Regression problem: idenfying predictor variables) The Berlin data are very recent and were obtained from Inside AirBnB. Download Date: 17th September 2020. Scraping Date: 30th August 2020. The files loaded are the listings.csv (all active accommodation places for Berlin) and the calender.csv (availability of accommodations with date and price). Inside AirBnB serves a map of all the data set samples: Distribution of samples map. The Jupyter/Python notebook for this analysis can be found here. Figure summary: The price distribution shows that the majority of listings are Private rooms and Entire home/apt. The Private room category has the majority of its listings cheaper than Entire home/apt and also has a shorter tail. The room types Shared room and Hotel room have much fewer counts. Listings in the Shared room category are cheaper than Private rooms. Hotel room counts are almost indistinguishible. Figure summary: The room distribution on AirBnB Berlin is relatively balanced between private rooms (41%) and entire homes/apartments (56%). A much smaller proportion of 1% are shared rooms with other guests, which are hostel style accomodations, and another 1% are listed Hotel rooms. Figure summary: All room types combined, the top four most expensive districts are Pankow, Marzahn-Hellersdorf, Mitte, and Charlottenburg-Wilmersdorf. Marzahn-Hellersdorf is neither a central tourist district “Mitte” nor adjacent, which is counterintuitive. However, the highest prices of Pankow are explained because on its southern end lies the hot neighborhood “Prenzlauer Berg”, which is famous for art, night clubs, etc. The districts Spandau, Neukölln, Reinickendorf, and Lichtenberg are the least expensive. These least expensive districts are on the outer most perimeter of Berlin and have relatively few tourist destinations. Figure summary: Generally, listings of the room type category Hotel (purple) are most expensive of the four types. The category Entire homes/apt (olive) are the most expensive among the non-commercial listings. Private rooms (red) are often 25 USD cheaper than Entire homes/apt. Shared rooms (green) are least expensive. The Hotel category has in many districts the largest range in prices, which may pull the total median of a district higher. The median prices of Private rooms and Shared rooms do not decline in the same pattern as does entire Home/apartments but rather, is much more stable among districs. Generally speaking, within a listing category, there is no extreme variablility across districts. Figure summary: Colored bars indicate the price difference between superhost and non superhost listings. Entire homes/apartments offered by superhosts are more expensive that those offered by non-superhosts in the majority of districts with the exception of Marzahn-Hellersdorf. The largest superhost price premium has to be paid for Entire home/apt in Spandau. The price difference is generally larger for Entire home/apt than Private room, while it is minimized in Pankow, Lichtenberg, and Charlottenburg-Wilmersdorf. Where are Superhosts chaper? None of these bargain-Superhost districts are located near Berlin’s major tourist destinations in Mitte. This means it is probably a valid choice to pick a non-Superhost listing if a cheaper, central location is desired. Counterintuitively, superhosts do not charge a premium everywhere in Berlin. More remote districts are acceptable, then there may be savings possible with superhosts in few, select districts. In a user mindset – which factor or option is going to be most influential on the price of listings that are displayed on the website? Figure Summary: The Random Forest Regressor yielded the most important options driving price variability with a satisfactory model score of R2 = 0.88. They factors are are in descending importance: The month of booking is twice as important than the numer of people accommodated. Districts are not as influential as they are in other cities, such as Paris. As an investigation on the influence of the month I want to visualize the prices per listing type and month. Figure Summary: Private room prices almost double in Spring and Summer (March to July) and are almost on par with the more expensive room types. Entire home/apt listings also increas during this month, but much less pronounced. Hotel rooms have a drop in prices in August, which may or may not be correlated that the data was scraped in August and short-term booking was discounted. Shared rooms show very little variance across the year. I hope you found this helpful and please let me know if you are interested in learning about other aspects of Berlin’s AirBnB data. Thanks to Elizabeth Herdter, from whose Paris AirBnB Analysis I took inspiration and decided to run my own analysis on Berlin. Let the Computer name the Formation Structured data classification is one of the important and typical task in supervised machine learning (ML). Assigning categories to structured data, which can be anything stored in a spereadsheet, relational database content (SQL), csv file etc. Data conetents may be names, dates, addresses, credit card numbers, stock information, geolocation, etc. In this article, I would like to demonstrate how we can do data classification on geophysical data using Python, XGBoost, and a little bit of Scikit-Optimize to predict sedimentological facies. The Society of Exploration Geophysicists (SEG), Matt Hall (Agile), and Brendon Hall (Enthought) ran in 2016 a competition on who can create the best Machine Learning model in classifying sedimentary facies in several wells using wireline measurements. For the dataset provided, a subject-matter expert (e.g., sedimentologist) manually described core sections and gave the facies names, which is calles labeling. This complete dataset can be used to train a Machine Learning Model. Note that in Artificial Intelligence rules are not hard-coded as in traditional programming, rather we give the computer the inputs and outputs, and the let it figure out the rules. These rules can then be used to make predictions on new, unseen, data. In this case we can then use new wireline data to predict sedimentological facies. The dataset, along with instructions were made available online in an article in SEG The Leading Edge “Facies classification using machine learning”. The article included a link to some starter code in a Jupyter notebook with a simple Support Vector Machine model that had to be surpassed in accuracy. In 2017, the results of the SEG competition were published in the SEG Leading Edge journal including all submission files for contestants to learn from each other. Teams were allowed to send new and improved models until the deadline. Two years later Brandon Hall penned a brief lookback on the merits, aftermath, and innovations that have been sparked by the ML contest he co-organized. The goal of this discussion is working through what a good submission did to improve on the starter code, but does not necessarily have to be the winning submission. Since the ML contest took place the XGBoost ensemble learning algorithm has taken on larger popularity. However, it not that easy to use, since there are many, many hyperparameter to tune. For that reason I decided to utilize Scikit Optimize, which was released first in August 2016, and I would like to see what benefits it has over Grid Search or Random Search, which was commonly used at the time of the ML contest. What does the data set look like? Originally, the SEG data were provided by the University of Kansas on the Hugoton and Panoma gas fields in SW Kansas ( Tim Carr and Robert S. Sawin (1996) Hugoton Natural Gas Area of Kansas, Kansas Geological Survey, Public Information Circular (PIC) 5). Encountered facies are interbedded deposits of carbonate (limestone and dolomite) and shale. The train dataset contains over 4000 training samples from ten different wells that were measured at half-foot downhole distances. These samples contain seven features (predictor variables). The seven features are: gamma ray (GR), resistivity (ILD_log10), photoelectric effect (PE), density/neutron porosity difference (DeltaPHI), average density/neutron porosity (PHIND), nonmarine/marine indicator (NM_M), and relative position (RELPOS). The test set was labeled by geologists with the correct facies information. Additionally, a test set of 800 samples was provided containing two wells but without facies labels. Goal is to train a classifier on the training set and predict correct facies on the test set. However, the true test labels remain unknown to the contestants. The published test-set F1 scores were calculated by the organizers. The best submitted classifier had an F1 score of 0.641 on the test set! This is something we can work with and strive to beat. +Only present in test set, cannot be trained. Prerequisites to follow this example are Python version 3 and Jupyter notebook. You can just install Anaconda and it will get everything for you. Also, little bit of Python and ML basics including data classification is required. We will be using XGBoost and Scikit-learn (Python) libraries for our example. Having installed Anaconda, you open the Anaconda Navigator and land on the Home screen. There, click the Install button for JupyterLab to make it accessible in future. Next, update all the libraries includied. Click on the Anaconda home screen on “CMD.exe Prompt” and enter Downloads: The classification problem can be divided into the following steps: Open Jupyter Lab (see screenshot above) and navigate in the file system pane on the left to the folder of the downloaded notebok Import necessary libraries. If you never worked with these then you may have to install them first with First, read the training data from csv to a Pandas dataframe, define the logging parameter names, facies names, and some standardized facies colors. At the end of this cell, impute all missing values (especially in the “PE” parameter) with the average of the parameter. Each parameter compared with each other. Colors pertain to facies type. How abundant are facies across all wells? How complete is the data after imputing? Show the first well in the training set! Augmentation is a crucial step in improving prediction quality. The process takes features and depths and calculates new features with a sliding window moving across depth. The first cell contains the XGBoost classifier controlled by the Scikit-Optimize (Skopt) “BayesSearchCV” function. There are two main differences when performing Bayesian Optimization using Skopt’s BayesSearchCV. When creating your search space you need to make each hyperparameter’s space a probability distribution as opposed to using lists like GridSearchCV. Skopt makes this easy for you with their library skopt.space which lets us import “Real”, “Integer”, and “Categorical” to create the probability distributions. Below you can see examples of using both the categorical and integer functions. For categorical spaces simply input a list inside the function. For Integer spaces input the minimum and maximum values you want BayesSearchCV to explore. The function on_step allows us to implement a form of early stopping (if needed) and also prints out the score after each iteration. The following cell brings everything together and starts the XGBoost algorithm and predicts test and train facies labels. Hyperparameter searching can be tedious, but there are tools that can do the tedious work for you. For example, Bayesian Optimization improves accuracy similarly as a Grid Search or Randomized Search, but automatically improves accuracy within the ranges given in the search space. Note that the Bayesian Optimization starts with randomized hyperparameters. This means it can sometimes require more iterations to arrive at the best accuracy possible. In my experience, the algorithm could reach maximum after 50 iterations, sometimes after 150. Play with the iterations and avoid excessive training durations since it takes longer and longer to improve the score. There will be a point of diminishing returns. The train F1 achieved here was 0.571. The F1 score of predicted test labels vs ground truth test labels was calculated by the organizers. Luckily, the correct test facies labels were provided in the GitHub repo after the contest concluded so we can calculate this by ourselves using the F1 scorer provided in Scikit-Learn. The F1 Scorer receives the variables y_hat_ts and y_ts_true. The test F1 achieved here was 0.42. It is unclear how the organizers calculated the Test F1. Normally, test/validation scores (unknown data) are lower than training scores but here they are higher. What is wrong here? Due to the proprietary nature of many geoscience data, the data size is limited to what was provided in the SEG ML contest, which is a relatively small data set compared to what treasure troves the AI pioneers in the tech sector can dispose of. Many of the algorithms common today work bettter (generalize more reliably) with massive data sets that are much larger than the 4000 samples used here. While Scikit-Optimize and XGBoost did not dramatically improve the accuracy of the model, it does simplify the model setup and resulted in a best score for the training set F1. However, this provides a stepping stone for geoscientists to further explore and apply machine learning techniques to lithofacies prediction, while employing their domain knowledge to further enhance the speed and accuracy of predictive models. Potential applications include validating velocity models for seismic data, fault interpretation and well top interpretation. Thanks to Matt Hall (Agile) and Brendon Hall (Enthought) for organizing the SEG Machine Learning challenge and the Kansas Geological Survey for their data. Hall, B. (2016). Facies classification using machine learning. The Leading Edge, 35(10), 906-909. The final step in the work with seismic data is seismic interpretation. The seismic data acquisition andc analysis worlfow goes through many steps as you can see (abbreviated) in the cover picture. The final step is seismic interpretation. In the scientific field called geophysics, interpretation sounds highly subjective. Very different from the usual statistics, ray and wave phenomena that can be calculated in detail. How can that be right? I would enjoy to say that interpretation is straight forward and seismic data reveals the perfect image of the subsurface for making business decisions. But it is not. Any way we manipulate seismic data has one single purpose: revert the filtering effect, distortion, and noise of the subsurface on our data to make the picture clearer. Of course, each step is based on assumptions. Imagining all the steps geophysicists undertake to improve up the image quality, it is sometimes amazing you can make any use of seismic data at all. After all the pre-processing the geophysicist is left with something like in the image below: This seismic image is easy on the eyes: low noise and great contrast. You can even see some hydrocarbons! At least if the interpreter knows what they are looking at. The upper depositional unit is made up of Pliocene-age sediments. They are layered like pan cakes, which usually indicates some kind of marine or lacustrine deposition history. You see some strong contrasts in an upwards-buckling structure. The rounded structure consists of evaporites (e.g., salt, gypsum, anhydrite). An upward-buckling structure like that is called an anticline and is the most old-fashioned and easiest means of how the hydrocarbon industry (oil and gas) obtains their product. The hydrocarbons are lower density than the rock and water inside the rock formation so that they rise up. In such anticline structures hydrocarbons get trapped below a sealing (non-pearmeable) rock formation and build a reservoir volume. Within this anticline structure you see something that cannot form syn-depositionally: There are two lines crossing at a pointy angle. The convex anticline crosses an almost straight (horizontal) line. This indicates that there has to be something else causing this peculiar shpe. These so-called flat spots can be a direct indicator for hydrocarbons trapped. The Flat Spot is a special Direct Hydrocarbon Indicator (DHI). The gas and oil in the rock posess a very much different accoustic impedance for our seismic signal than the regular rock. Now the really interesting part of the story is, that you (the reader) were very probably able to follow this explanation of the flat spot. But there is a high probability that you and I were not looking at exactly the same flat structure. Seismic interpreters working with a single seismic image will interpret it in different ways. The following image from https://pickthis.io, a social image interpretation web-app, is a stacked graph of ~40 interpreters’s opinions (more overlap = hotter). Science can explain these patterns well, but finding them is still highly subjective. You can see that the heatmap shows many picks along the flat spot described. This is especially interesting as I posed the challenge to pick the “hydrocarbon indication” instead of directly giving out the challenge “find the flat spot”, giving us many more interpretations. This starts becoming a problem when companies require hard volume numbers on how much hydrocarbons are trapped in the structure (or none at all??). These volumes go into larger risk calculations if the company wants to invest in drilling the structure or not. The interpretation is a make-or-break situation and such requires experience and at best multiple sets of eyes. For building up your interpretation experience, I encourage you to sign up with https://pickthis.io and take the challenge for yourself. Note: Only after submitting your interpretation you can see the others’. Be relieved, there is no wrong interpretation, just look at it and get going. If you know your way in geophysical interpretation already, then this is a perfect training opportunity without wagering your company’s exploration budget. Task: Pick the location and extent of the largest normal fault. Description: Seismic section through Penobscot 3D seismic volume. Task: Pick the fault and analyze the structure. Description: Pick the fault along the cross section. Task: Pick a single consolidated salt body from the depth migrated seismic image. Description: Image created by slicing and modifying an openly available 3D depth migrated image of the SEAM Phase 1 salt body. Task: Pick the thrust fault planes. Description: Duplicated and folded strata from the Horton Bluff formation at Rainy Cove, Nova Scotia.. PhD Résumé and CoverLetter Template

Introduction
How to
Preview
Résumé


CoverLetter

Physicists Dissecting "Interstellar"

Accurate Science Fiction?
Bonus
Reading in 2020

Introduction
R.S. Sutton and A.G. Barto: “Reinforcement Learning: An Introduction”

G.R.R Martin: “A Dance with Dragons”

P. Domingos: “The Master Algorithm”

C. Thompson: “Coders”

S. Pinker: “The Sense of Style”

Fashion MNIST

Introduction

Hands-On
R, the following functions should do the job and load the training and test cases including class labels into the global environment. The code was provided by <href=”https://gist.github.com/brendano/39760” target=”_blank”>Brendan O’Connor</a>:load_mnist <- function() {
load_image_file <- function(filename) {
ret = list()
f = file(filename,'rb')
readBin(f,'integer',n=1,size=4,endian='big')
ret$n = readBin(f,'integer',n=1,size=4,endian='big')
nrow = readBin(f,'integer',n=1,size=4,endian='big')
ncol = readBin(f,'integer',n=1,size=4,endian='big')
x = readBin(f,'integer',n=ret$n*nrow*ncol,size=1,signed=F)
ret$x = matrix(x, ncol=nrow*ncol, byrow=T)
close(f)
ret
}
load_label_file <- function(filename) {
f = file(filename,'rb')
readBin(f,'integer',n=1,size=4,endian='big')
n = readBin(f,'integer',n=1,size=4,endian='big')
y = readBin(f,'integer',n=n,size=1,signed=F)
close(f)
y
}
train <<- load_image_file('train-images-idx3-ubyte')
test <<- load_image_file('t10k-images-idx3-ubyte')
train$y <<- load_label_file('train-labels-idx1-ubyte')
test$y <<- load_label_file('t10k-labels-idx1-ubyte')
}
show_digit <- function(arr784, col=gray(12:1/12), ...) {
image(matrix(arr784, nrow=28)[,28:1], col=col, ...)
}
library(reshape2)
library(ggplot2)
showExamples <- function(nExamplesClass = 10, randomize = F) {
classes <- sort(unique(train$y)) # a vector of all classes
nClasses <- length(classes) # Number of classes
iExamples <- as.matrix(sapply(classes,
function(i) {
iLab <- which(train$y == i)
sample(x = iLab, size = nExamplesClass, replace = F)
}))
if(randomize) {
iExamples <- matrix(sample(x = iExamples, size = length(iExamples), replace = F),
nrow = dim(iExamples)[1])
}
data <- array(train$x[iExamples, ], dim = c(nExamplesClass * nClasses, 28, 28))
plotData <- melt(data, varnames = c("image", "x", "y"), value.name = "pixel")
nrows <- if(randomize) round(sqrt(nExamplesClass * nClasses)) else 10
p <- ggplot(plotData, aes(x = x, y = y, fill = pixel)) +
geom_tile() +
scale_y_reverse() +
facet_wrap(~ image, nrow = nrows) +
theme_bw()+
theme(
panel.spacing = unit(0, "lines"),
axis.text = element_blank(),
axis.ticks = element_blank(),
strip.background = element_blank(),
strip.text.x = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
legend.position = "none",
axis.title.x = element_blank(),
axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
axis.title.y = element_blank(),
axis.text.y = element_blank(),
axis.ticks.y = element_blank()
) + scale_fill_gradient(low = "black", high = "white")
plot(p)
}
showExamples(20, T) we can plot a 20x20 matrix with 400 random images: 

Google ML introducing Fashion MNIST
A Peek Behind the ML Curtain

estimated with the rigor of our choosing. In statistics, this concept is formalized in estimation theory. This article shows how this can be applied to ML and how we quantify the quality of a model. Since ML models can generally not be perfect for complex problems, it is useful to try to describe how good they are.Estimator Properties
Bias
Variance

Bias-Variance Tradeoff

Gradient Descent
Full-Batch Gradient Descent
Stochastic Gradient Descent
Mini-Batch Gradient Descent

Conclusion
gem "kramdown-math-katex" What to expect from an Online Hackathon

Pros
Cons
Results

My Verdict
Smart AirBnB booking in Berlin

Purpose of this Analysis
 Image Source: mapsland.com
Image Source: mapsland.comData Source
Analysis Steps
Results
A. How are the prices distributed?

B. What is the room type breakdown?

C. What is the median listing price by room type and district?


Image Source: modified after mapsland.com
D. What is the difference in price between super host and non super host listings?

E. Which website options influence the price?


Analysis Summary
Acknowledgements
Sedimentary Facies Machine Learning - XGBoost with Intelligent Bayesian Optimization

Introduction
Facies Description Label Adjacent facies 1 Nonmarine sandstone SS 2 2 Nonmarine coarse siltstone CSiS 1,3 3 Nonmarine fine siltstone FSiS 2 4 Marine siltstone and shale SiSh 5 5 Mudstone MS 4,6 6 Wackestone WS 5,7,8 7 Dolomite D 6,8 8 Packstone-grainstone PS 6,7,9 9 Phylloid-algal bafflestone BS 7,8 11 Marine sandstone+ N/A 4,6,8 
conda update --all --y. This will online-update all the pre-installed libraries. But you will need more for this project that will install in the latest version.Let’s get going!
!conda install matplotlib for example.%matplotlib inline
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn import preprocessing
from xgboost.sklearn import XGBClassifier
from skopt import BayesSearchCV
from skopt.space import Real, Categorical, Integer
from scipy.signal import medfilt
from sklearn.metrics import f1_score
from classification_utilities import make_facies_log_plot
from classification_utilities import compare_facies_plot
Step 1: Load
data = pd.read_csv('facies_vectors.csv')
# Define groups of parameters
# Wireline measurements -> lnput features
feature_names = ['GR', 'ILD_log10', 'DeltaPHI', 'PHIND', 'PE', 'NM_M', 'RELPOS']
# Geological descriptins -> labels
facies_names = ['SS', 'CSiS', 'FSiS', 'SiSh', 'MS', 'WS', 'D', 'PS', 'BS']
# Color codes
facies_colors = ['#F4D03F', '#F5B041','#DC7633','#6E2C00', '#1B4F72','#2E86C1', '#AED6F1', '#A569BD', '#196F3D']
# Store features and labels
X = data[feature_names].values
y = data['Facies'].values
# Store well labels and depths
well = data['Well Name'].values
depth = data['Depth'].values
# Fill 'PE' missing values with mean
imp = SimpleImputer(missing_values=np.nan, copy=False, strategy="mean")
imp.fit(X)
X = imp.transform(X)
Step 2: Explore
Data Exploration: Feature distribution
def plot_feature_stats(X, y, feature_names, facies_colors, facies_names):
# Remove NaN
nan_idx = np.any(np.isnan(X), axis=1)
X = X[np.logical_not(nan_idx), :]
y = y[np.logical_not(nan_idx)]
# Merge features and labels into a single DataFrame
features = pd.DataFrame(X, columns=feature_names)
labels = pd.DataFrame(y, columns=['Facies'])
for f_idx, facies in enumerate(facies_names):
labels[labels[:] == f_idx] = facies
data = pd.concat((labels, features), axis=1)
# Plot features statistics
facies_color_map = {}
for ind, label in enumerate(facies_names):
facies_color_map[label] = facies_colors[ind]
sns.pairplot(data, hue='Facies', palette=facies_color_map, hue_order=list(reversed(facies_names)))
plot_feature_stats(X, y, feature_names, facies_colors, facies_names)

Data Exploration: Facies distribution
# workaround to increase figure size
mpl.rcParams['figure.figsize'] = (20.0, 10.0)
inline_rc = dict(mpl.rcParams)
# Data Exploration: Facies per well
for w_idx, w in enumerate(np.unique(well)):
# Define plot ID in mosaic
ax = plt.subplot(3, 4, w_idx+1)
# Define histogram settings
hist = np.histogram(y[well == w], bins=np.arange(len(facies_names)+1)+.5)
plt.bar(np.arange(len(hist[0])), hist[0], color=facies_colors, align='center')
# Cosmetic settings
ax.set_xticks(np.arange(len(hist[0])))
ax.set_xticklabels(facies_names)
ax.set_title(w)

Data Exploration: Features per well present
for w_idx, w in enumerate(np.unique(well)):
# Define plot ID in mosaic
ax = plt.subplot(3, 4, w_idx+1)
# Define histogram settings
hist = np.logical_not(np.any(np.isnan(X[well == w, :]), axis=0))
plt.bar(np.arange(len(hist)), hist, color=facies_colors, align='center')
# Cosmetic settings
ax.set_xticks(np.arange(len(hist)))
ax.set_xticklabels(feature_names)
ax.set_yticks([0, 1])
ax.set_yticklabels(['miss', 'hit'])
ax.set_title(w)

make_facies_log_plot(data[data['Well Name'] == 'SHRIMPLIN'], pred_column='Facies', facies_colors=facies_colors)

Step 3: Augmentation
# Feature windows concatenation function
def augment_features_window(X, N_neig):
# Parameters
N_row = X.shape[0]
N_feat = X.shape[1]
# Zero padding
X = np.vstack((np.zeros((N_neig, N_feat)), X, (np.zeros((N_neig, N_feat)))))
# Loop over windows
X_aug = np.zeros((N_row, N_feat*(2*N_neig+1)))
for r in np.arange(N_row)+N_neig:
this_row = []
for c in np.arange(-N_neig,N_neig+1):
this_row = np.hstack((this_row, X[r+c]))
X_aug[r-N_neig] = this_row
return X_aug
# Feature gradient computation function
def augment_features_gradient(X, depth):
# Compute features gradient
d_diff = np.diff(depth).reshape((-1, 1))
d_diff[d_diff==0] = 0.001
X_diff = np.diff(X, axis=0)
X_grad = X_diff / d_diff
# Compensate for last missing value
X_grad = np.concatenate((X_grad, np.zeros((1, X_grad.shape[1]))))
return X_grad
# Feature augmentation function
def augment_features(X, well, depth, N_neig=1):
# Augment features
X_aug = np.zeros((X.shape[0], X.shape[1]*(N_neig*2+2)))
for w in np.unique(well):
w_idx = np.where(well == w)[0]
X_aug_win = augment_features_window(X[w_idx, :], N_neig)
X_aug_grad = augment_features_gradient(X[w_idx, :], depth[w_idx])
X_aug[w_idx, :] = np.concatenate((X_aug_win, X_aug_grad), axis=1)
# Find padded rows
padded_rows = np.unique(np.where(X_aug[:, 0:7] == np.zeros((1, 7)))[0])
return X_aug, padded_rows
4. Train, then Predict Test Facies
search_space = {"colsample_bylevel": Real(0.6,1),
"colsample_bytree":Real(0.6, 0.8),
"gamma": Real(0.01,5),
"learning_rate": Real(0.0001, 1),
"max_delta_step": Real(0.1, 10),
"max_depth": Integer(3, 15),
"min_child_weight": Real(1, 500),
"n_estimators": Integer(10,200),
"reg_alpha": Real(0.1,100),
"reg_lambda": (0.1, 100),
"subsample": (0.4, 1.0)
}
def on_step(optim_result):
"""
Callback meant to view scores after
each iteration while performing Bayesian
Optimization in Skopt"""
score = XGB_bayes_search.best_score_
print("best train score: {}".format(score))
# Train and test a classifier
def train_and_test(X_tr, y_tr, X_ts, well_ts):
# Feature normalization
scaler = preprocessing.RobustScaler(quantile_range=(25.0, 75.0)).fit(X_tr)
X_tr = scaler.transform(X_tr)
X_ts = scaler.transform(X_ts)
# Train classifier
clf = XGBClassifier()
global XGB_bayes_search
XGB_bayes_search = BayesSearchCV(clf, search_space, n_iter=75, scoring="f1_weighted", n_jobs=-1, cv=5)
XGB_bayes_search.fit(X_tr, y_tr, callback=on_step)
# Test classifier
y_ts_hat = XGB_bayes_search.predict(X_ts)
# Clean isolated facies for each well
for w in np.unique(well_ts):
y_ts_hat[well_ts==w] = medfilt(y_ts_hat[well_ts==w], kernel_size=5)
return y_ts_hat
# Load testing data
test_data = pd.read_csv('validation_data_nofacies.csv')
# Prepare training data
X_tr = X
y_tr = y
# Augment features
X_tr, padded_rows = augment_features(X_tr, well, depth)
# Removed padded rows
X_tr = np.delete(X_tr, padded_rows, axis=0)
y_tr = np.delete(y_tr, padded_rows, axis=0)
# Prepare test data
well_ts = test_data['Well Name'].values
depth_ts = test_data['Depth'].values
X_ts = test_data[feature_names].values
# Augment features
X_ts, padded_rows = augment_features(X_ts, well_ts, depth_ts)
# Predict test labels
y_ts_hat = train_and_test(X_tr, y_tr, X_ts, well_ts)
# Add prediction to test_data for plotting
test_data['Prediction'] = y_ts_hat
# Predict train labels,
y_tr_hat = XGB_bayes_search.predict(X_tr)
# Add prediction to data for plotting
data = data.join(pd.DataFrame(y_tr_hat), how='inner')
data.rename(columns={0: "Prediction"}, inplace=True)
print("\nBest score: {}\nBest params: {}".format(XGB_bayes_search.best_score_,XGB_bayes_search.best_params_))
Step 5: Evaluate
# F1 score on test wells
y_ts_true = pd.read_csv('blind_stuart_crawford_core_facies.csv')
# rename columns for merging
y_ts_true.rename(columns={'Depth.ft': 'Depth', 'LithCode': 'Facies'}, inplace=True)
# remove facies "11", since that was not in training
y_ts_true = y_ts_true[y_ts_true!=11]
test_data = test_data.merge(y_ts_true, on='Depth', how='inner')
test_data.dropna(inplace=True)
print("F1_weighted: ",f1_score(test_data['Facies'], test_data['Prediction'], average='weighted'))
Place Team Train F1 Score Test F1 Score N/A ChristianHallerX 0.571 0.478 1 LA_Team (Mosser, de la Fuente) ??? 0.641 2 ispl (Bestagini, Tuparo, Lipari) 0.564 0.640 3 SHandPR 0.560 0.631 4 HouMath 0.563 0.630 5 esaTeam 0.566 0.629 # Compare true and predicted facies on first TREAINING well
compare_facies_plot(data[data['Well Name'] == 'SHRIMPLIN'], pred_column='Prediction', facies_colors=facies_colors)

# Compare true and predicted facies on first TEST well
compare_facies_plot(test_data[test_data['Well Name'] == 'STUART'], pred_column='Prediction', facies_colors=facies_colors)

# Compare true and predicted facies on second TEST well
compare_facies_plot(test_data[test_data['Well Name'] == 'CRAWFORD'], pred_column='Prediction', facies_colors=facies_colors)

Conclusion
Acknowledgements:
References
Friedman, J. H. (2000) Greedy function approximation: A gradient boosting machine: Annals of Statistics, 29, 1189–1232. Seismic Interpretation ... the Art and Science

Introduction
A Paleontologist, a Geologist, and a Geophysicist are interviewing for a job.
First, the Paleontologist is asked in to the Hiring Manager's office and the Paleontologist is shown a piece of paper with some wrtiting.
The Hiring Manager asks: "What do you see?" The Paleontologist quips "The number 4"
The Hiring Manager is continues the interview and then asks the Geologist into his office.
The Hiring Manager asks: "What do you see?" The Geologist looks at the paper and after short deliberation replies: "4.0".
Finally, the Hiring Manager beckons the Geophysicist into the office and hands him the paper.
He asks: "Geophysicist, what do you see?". The Geophysicist looks at the sheet for a long time, turns it upside down, thinks.
The Geophysicist leans forward and whispers: "What do you want it to be?"
Flat Spots

Joshua Doubek / pickthis.io Click me!
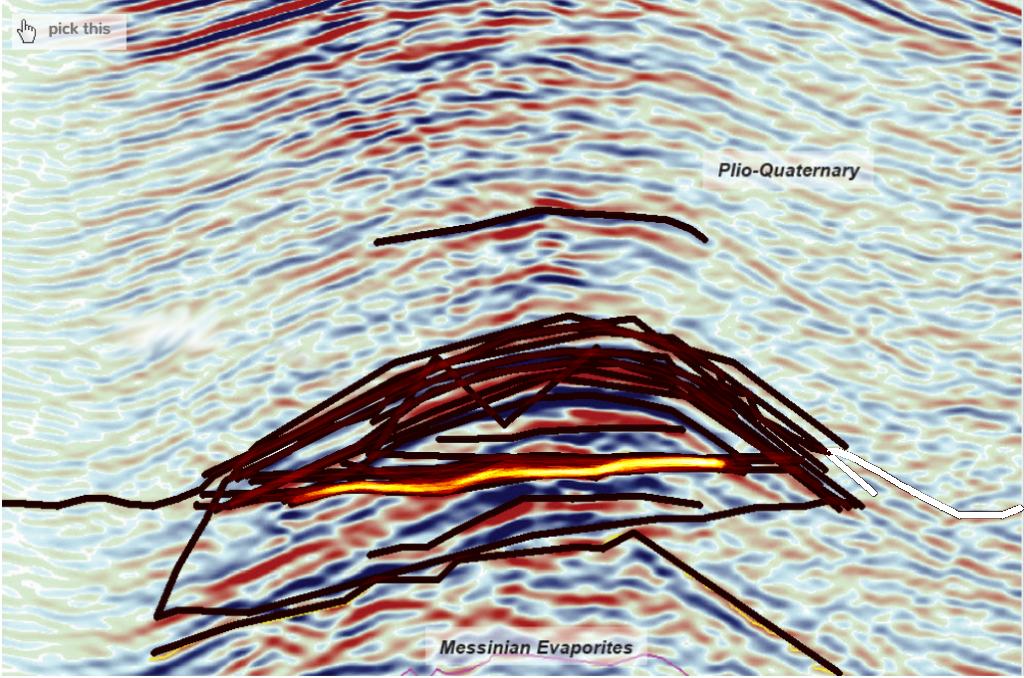
Joshua Doubek / pickthis.ioSome Examples from pickthis.io
Low resolution extensional faulting
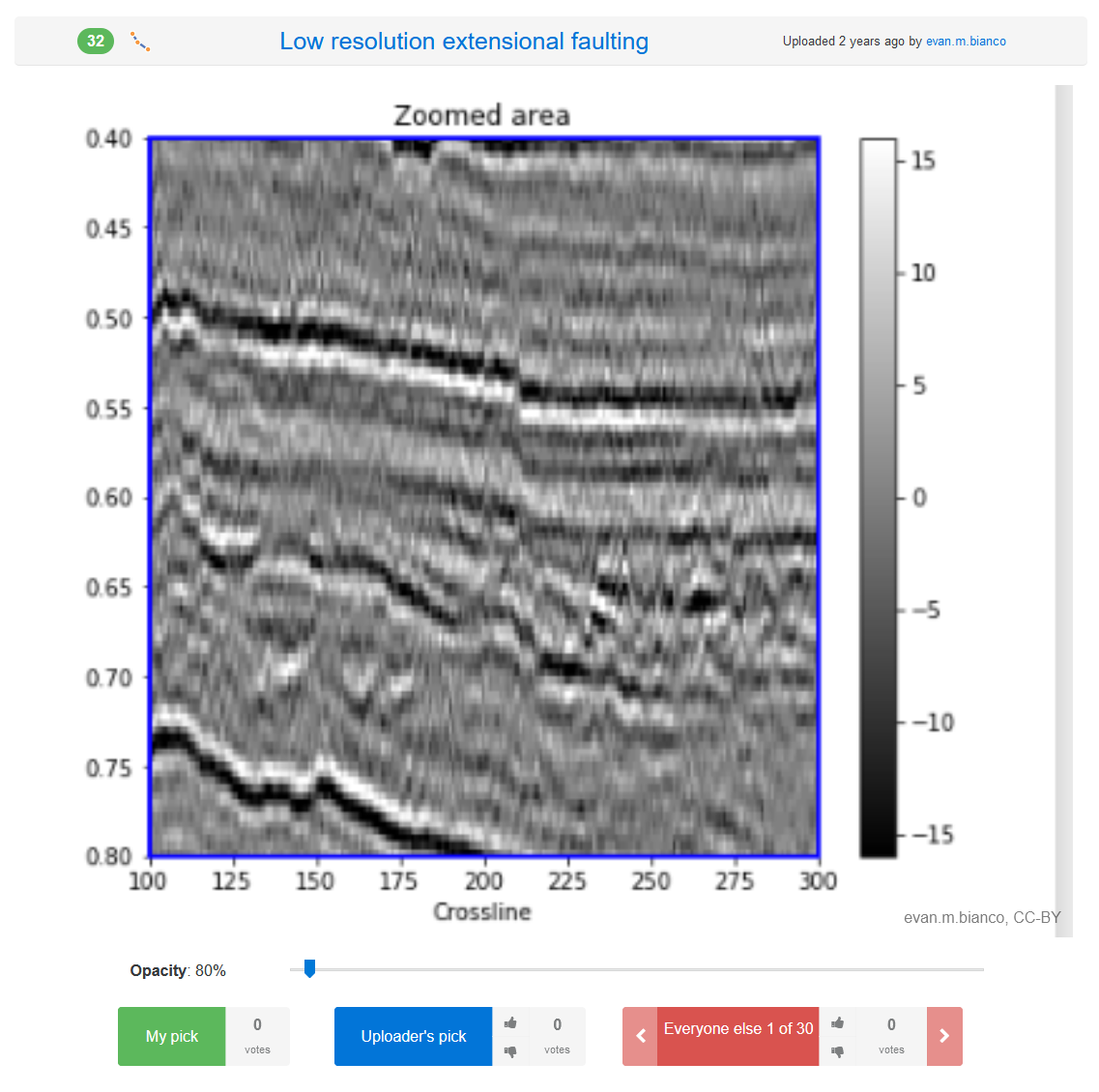
Evan M. Bianco / pickthis.io
Click me!
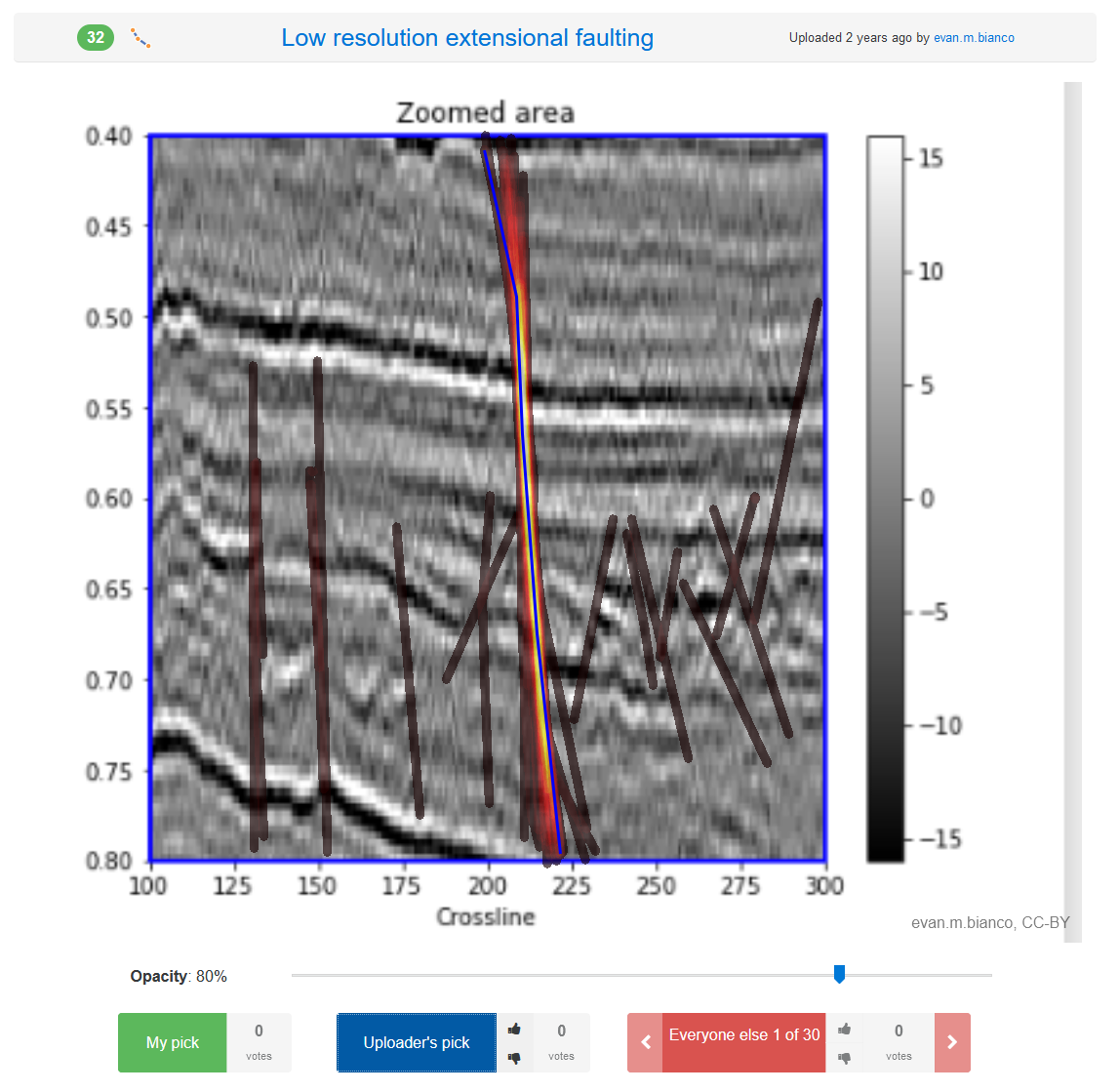
Evan M. Bianco / pickthis.ioPick the fault
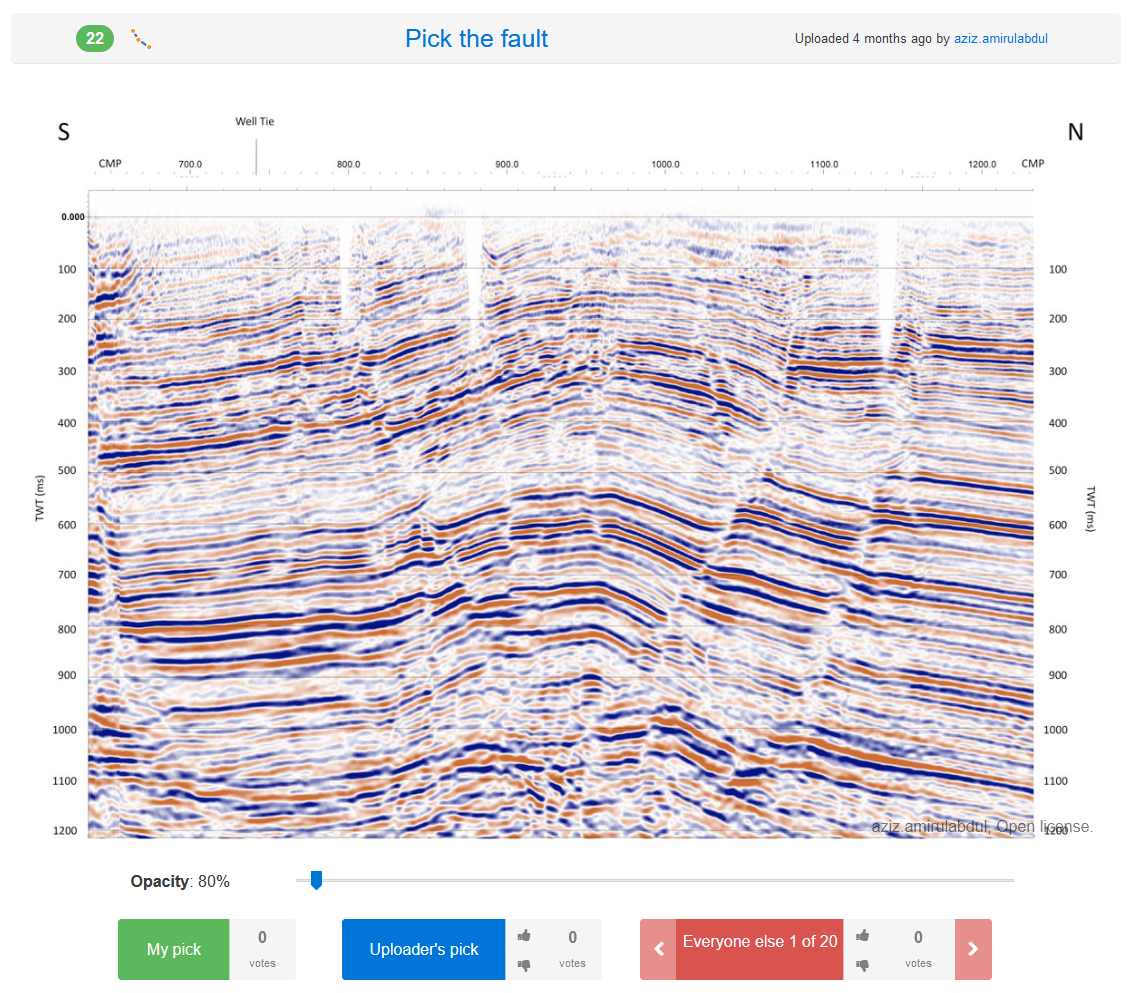
Aziz Amirul Abdul / pickthis.io
Click me!
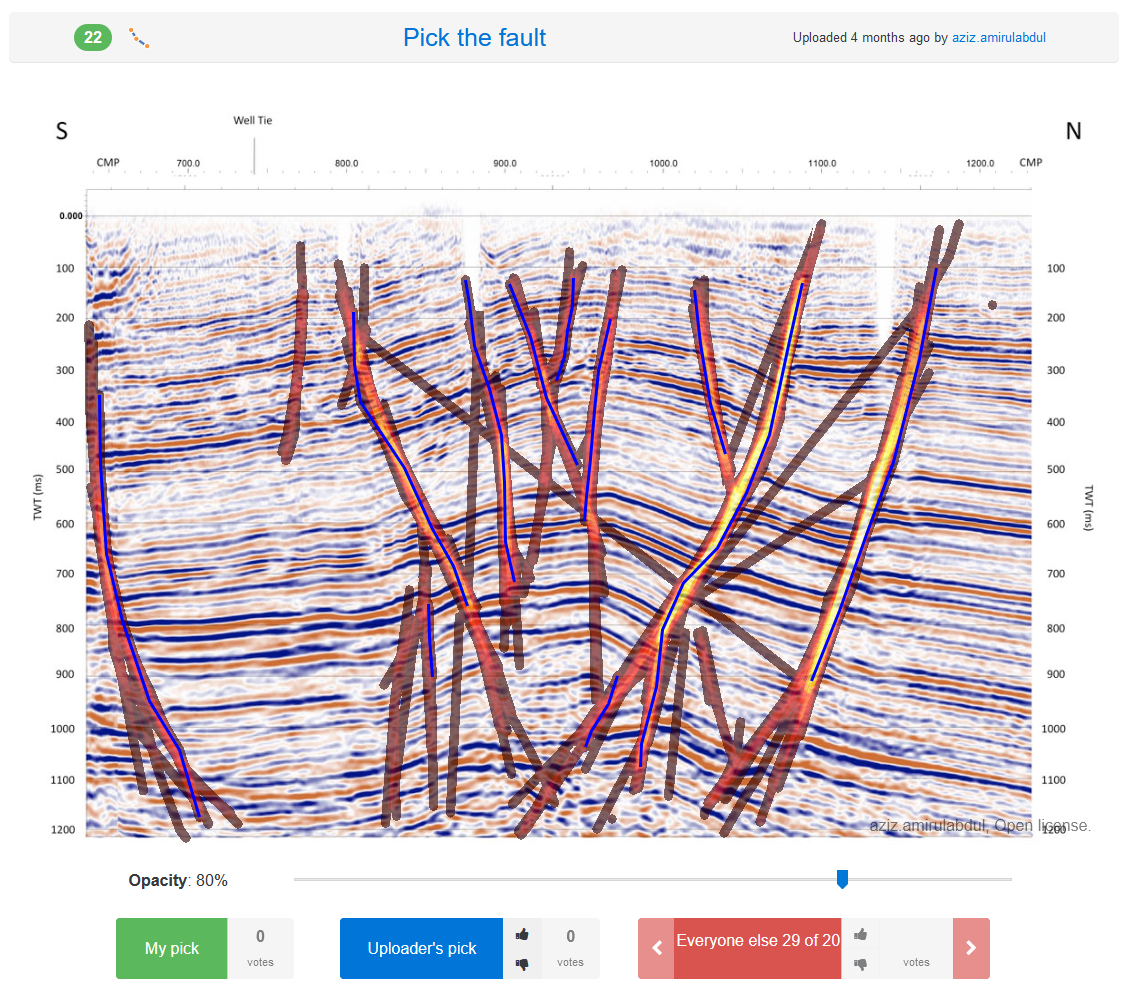
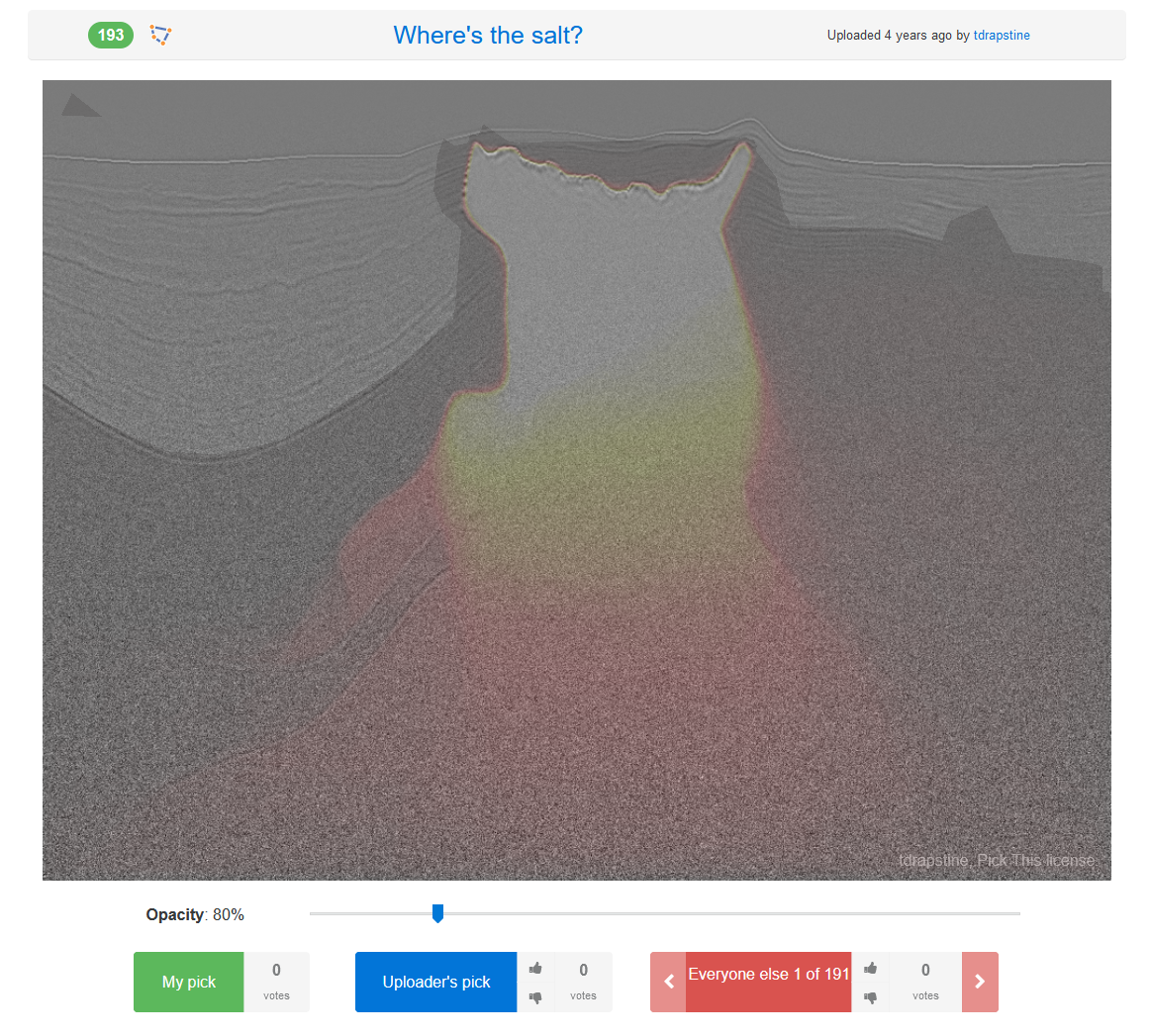
Aziz Amirul Abdul / pickthis.ioWhere’s the salt?
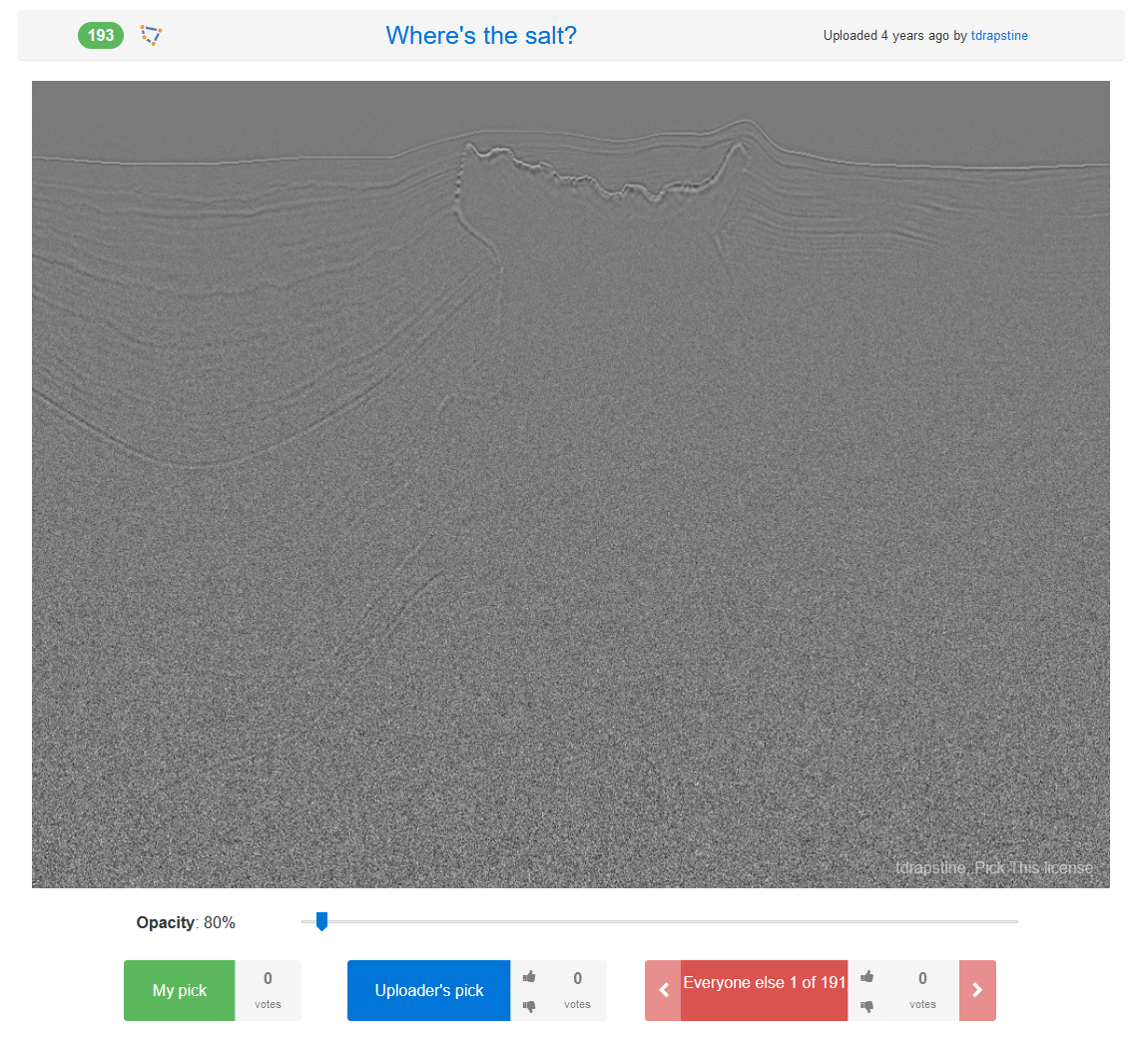
tdrapstine / pickthis.io
Click me!
tdrapstine / pickthis.ioThrust faults
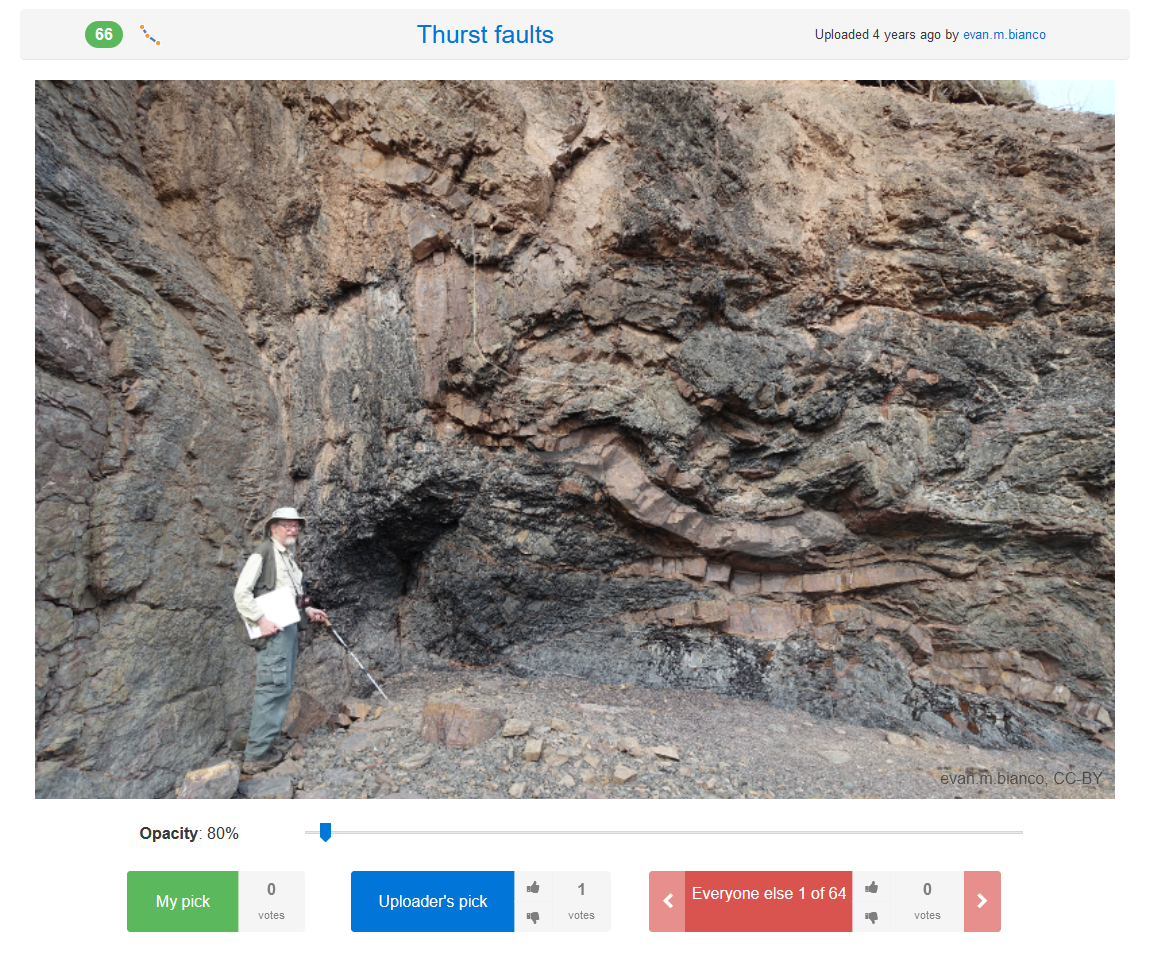
Evan M. Bianco / pickthis.io
Click me!
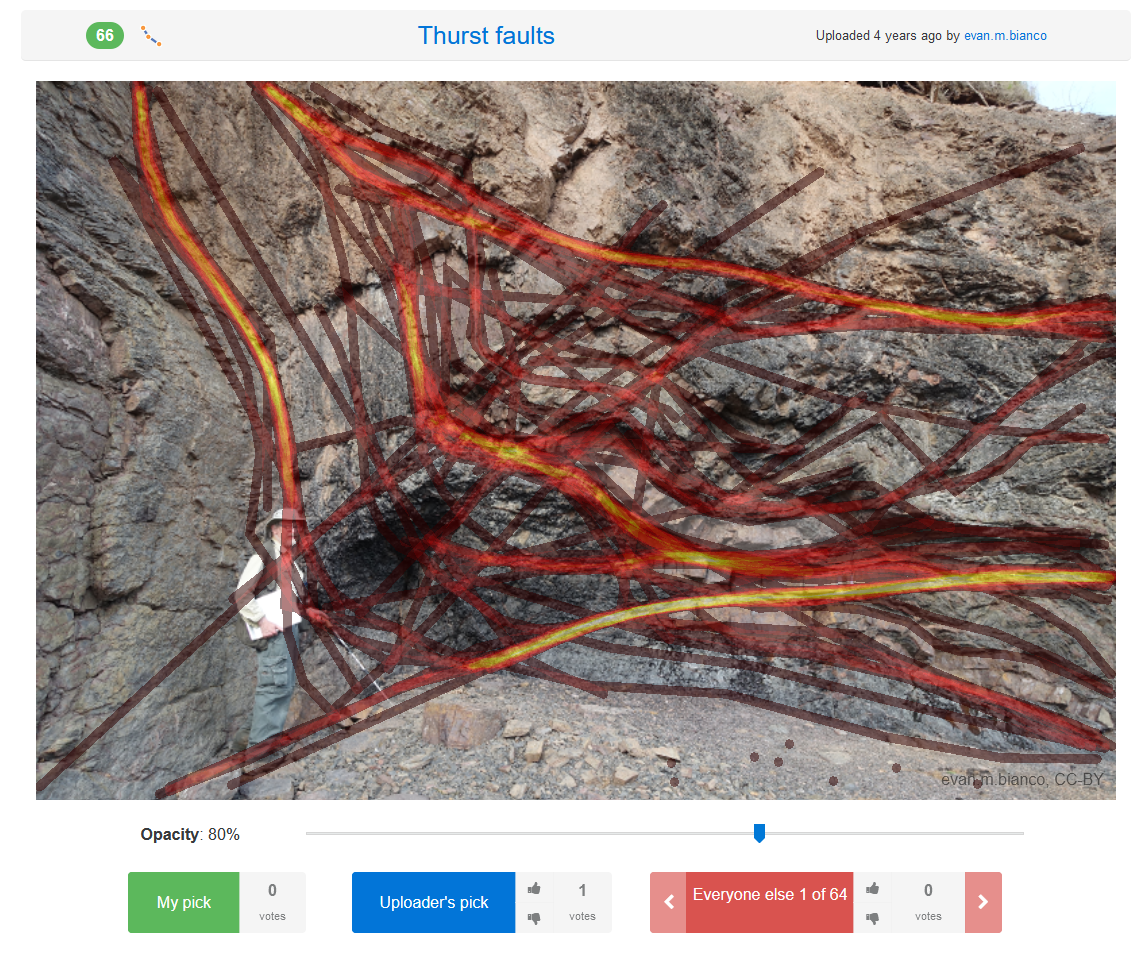
Evan M. Bianco / pickthis.ioPagination