Digital Rocks

Rock analysis is not only an analog process in the laboratory anymore.
- Introduction
- Step 1: Sampling
- Step 2: Scanning -> Slice Stack
- Step 3: Loading
- Step 4: Noise Removal
- Step 5: Image Segmentation
- Step 6: Disconnected Pores
- Step 7: Separate Unique Pores
- Step 8: Network Model
- Step 9: Flow Modeling
- Videos
Introduction
The need for small-scale analysis of rocks is a common necessity in academia and industry. Digital analysis is precise and manipulation in a computer is non-destructive to the sample. This is an important consideration if the sample is rare or was expensive to obtain.
Benefits of digital analysis are the easy measurement of desired volumina and subsequent use in simulations. Digitalisation is realized with X-ray computed tomography (CT or MicroCT) or Focused Ion Beam in a Scanning Electron Microscope (FIB/SEM, which is technically destructive in a small area, since the ion beam removes layer after layer). In either case, a stack of equidistant 2d slices is created and can be used to reconstruct a 3d volume.
When sample is to be characterized it is a common task to segment and visualize and quantify pores, pore throats, post-depositional crystalizations, pore shapes etc.
I want to describe how geologists go about quantifying porosity and then model permeability from digital rocks.
Step 1: Sampling
Take a hand sample, whole core, core plug, sidewall core in the field.
Step 2: Scanning -> Slice Stack
Scan the sample with the appropriate device for the size of the sample and required resolution. The CT device will scan the sample, create a virtual model, and then export a stack of black-and-white images (so-called “slices”).
Step 3: Loading
Import stack of slices into a digital rock analysis suite. In my case, I used ThermoFisher PerGeos.
Step 4: Noise Removal
Preprocess noisy images.

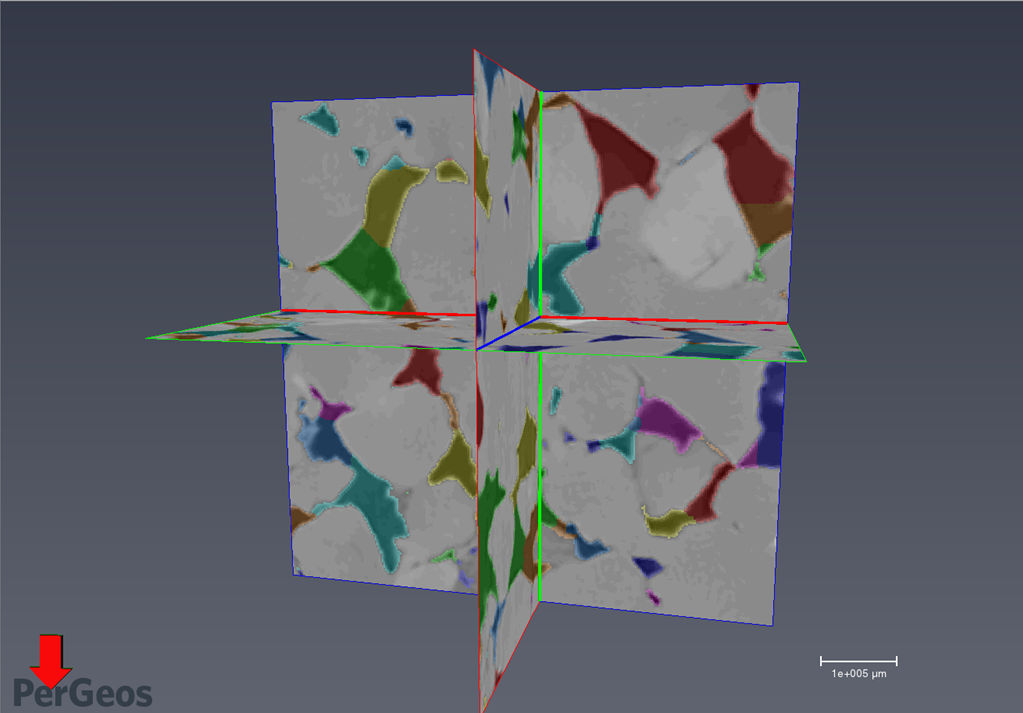
Step 5: Image Segmentation
Segment objects into classes. For example mask only the pores and assign them to class “pore space”, then mask the mineral grains etc. Various segmentation techniques exist: manual selection, magic wand, thresholding by color value, watershed. To avoid operator bias, a completely automatic routine such as wathershed should be used that delivers repeatable results.

Step 6: Disconnected Pores
Remove disconnected porosity (that has no permeability) from the total porosity and obtain the connected pore space.

Step 7: Separate Unique Pores
Divide the total pore space into separate pores and give each an identification.
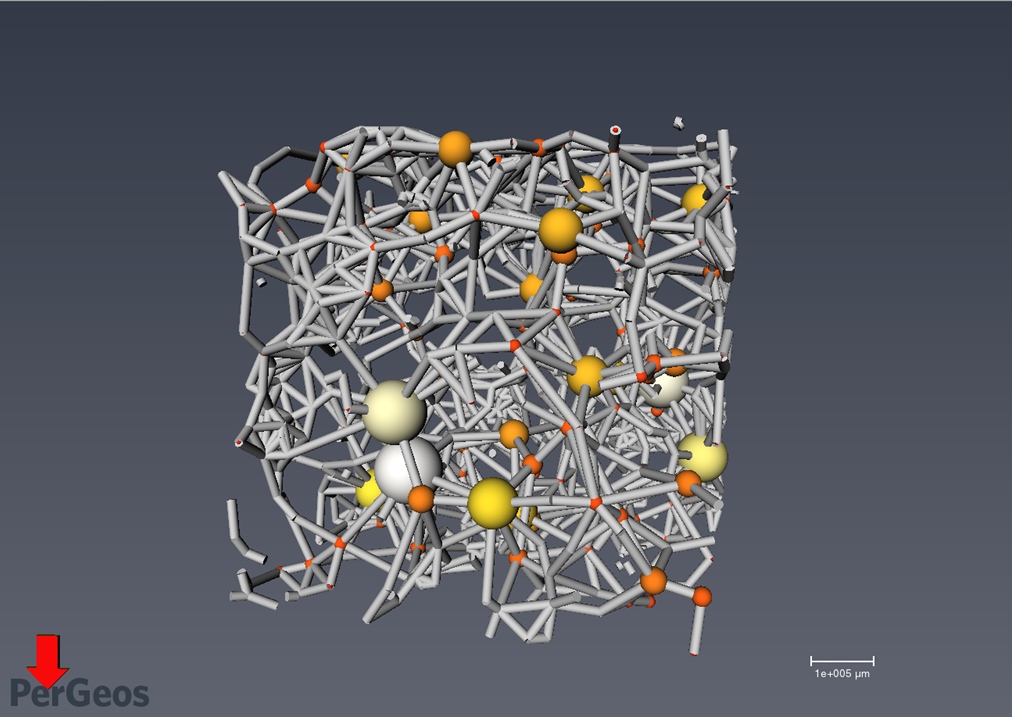
Step 8: Network Model
Generate a pore-network model.
Step 9: Flow Modeling
Model the pressure field and permeability/hydraulic conductivity (K) by setting fluid viscosity and other boundary conditions. Watch the vectorized flow pattern Single-Phase Flow Simulation through Sandstone.
Basically, this analysis pathway can also be applied to single thin sections, which were photographed under the optical microscope. In that case, no valid stack of equidistant slices is available. Some software suites can model the 3d stacking pattern of the grains if the type of rock is known. However, this is a much less quantitative approach.
The software used is ThermoFisher PerGeos 2019.4 with the freely available MicroCT dataset “Berea Sandstone Mini Plug”. More info about the Berea Sandstone and how it can be digitally processed in ThermoFisher PerGeos.
Videos
MicroCT Sandstone Porosity Segmentation
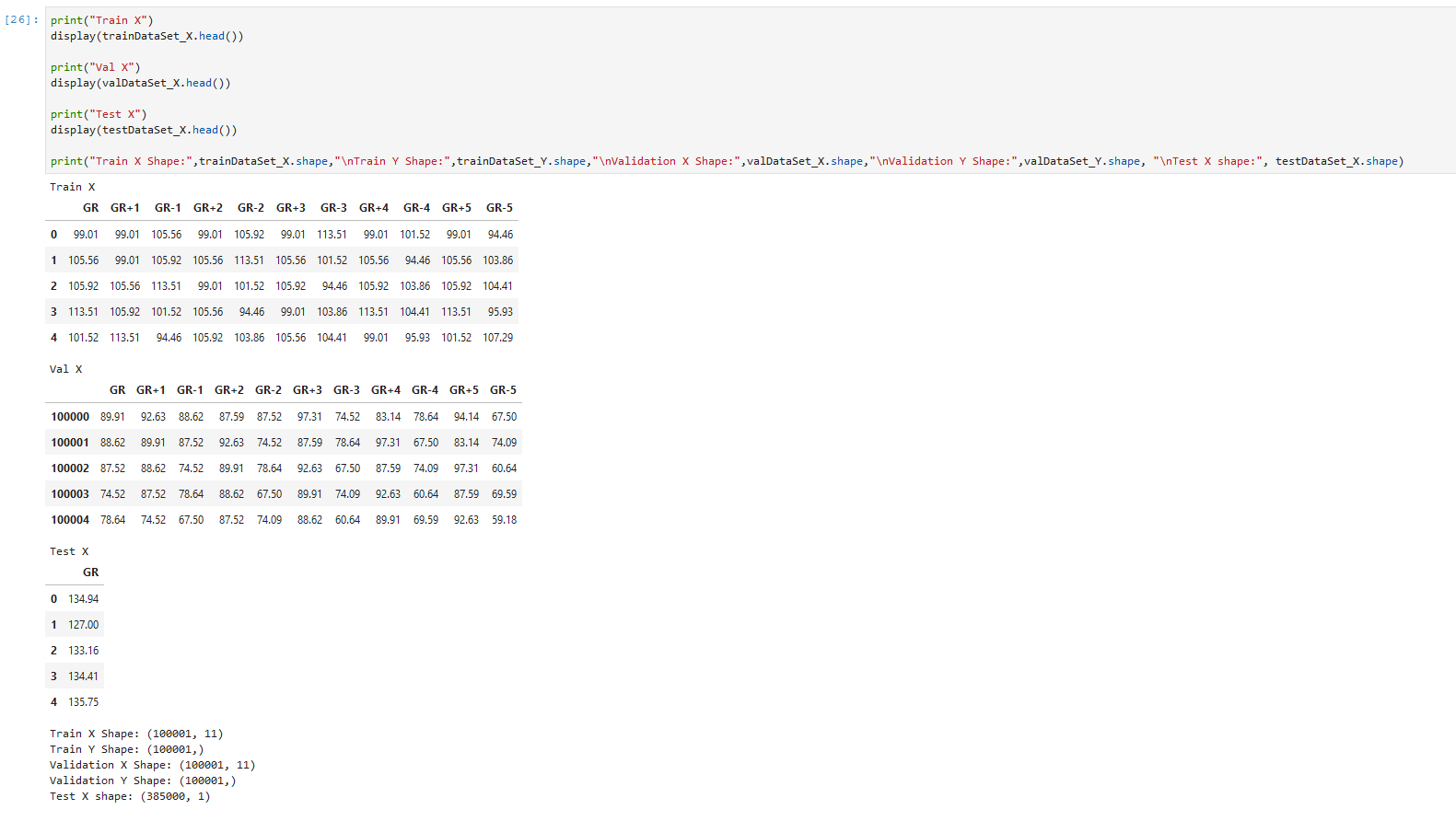
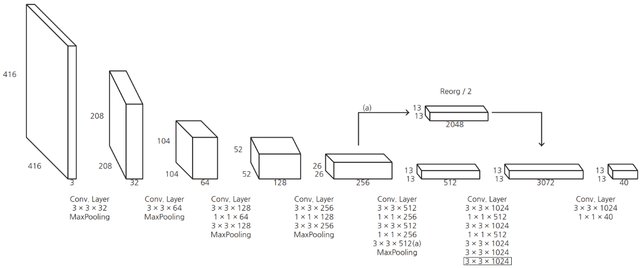
Single-Phase Flow Simulation through Sandstone Data Scientists and ML Researchers compete for the best geo-statistics algorithms on new competition platform. The Shell International Exploration and Production Inc. recently (November 2019) started a new webiste named XEEK (https://xeek.ai/challenges) with contests to predict facies from wireline logs via machine learning amongst many others. In many ways it is similar to Kaggle, but solution ways are not made public. Third-party, business-hosted, competitions for Machine Learning (ML) solutions have been around for a while on https://www.kaggle.com/, but geology-related problems used to be relatively rare. This is changing now with XEEK. Kaggle is known as not only hosting ML challenges, but also practice material. Experience Data Scientists share their solutions to competitions in notebooks called “kernels”. ConocoPhillips, Equinor (formerly Statoil), and many big tech companies have hosted challenges on Kaggle with large prizes. Why should you consider this except for the prize money? Well, Data Science and Machine Learning is a relatively new field with limited formal degrees available from universities. Few people have experience and most wearing that hat are cross-trained. That makes it much more important to show what you really can do and present a portfolio of problems you have worked with. If you are having trouple getting started, in addition to the problem description on the contest site, there is a file already available that explains how we can use machine learning to label Gamma Ray geometries from gamma ray logging tool (GR). The tutorial notebooks set you up to give you hands-on material to try it for yourself and at the end define the process to get the desired output file that you will submit. The main job for the participant is to try out their own approach and iteratively hone it for the duration of the contest. As I have not worked with a lot of demographic or IoT data, but not necessarily had access to large data sets of proprietary borehole data, I would like to take you on a journey how I dug my way into the topic. Taking workshops, courses and reading up on anything Data Scinece e.g., on https://towardsdatascience.com/ amongst many others will inevitably expose you to a Jupyter Notebook. It revolutionized the Python experience and makes sharing and developing code so much easier by viewing the results of an operation in a separate window or just next to the code. In fact, the concept is not unique to Python anymore as Jupyter also runs Ruby, Julia, Spark, R, and many more. Matlab has a similar feature with their “Live Script”, and of course R is now best used in R Studio. You may think this could take a long time to assemble such an environmernt with a lot of optional open source addons to tweak the experience - a huge hassle for a newcomer. Turns out, it is not. An easy way is installing the Anaconda suite, which comes with Jupyter built in. Start Jupyter Labs with one click and done. The coding work is done in a Jupyter notebook, with the file extension “.ipynb”, where you can select your pogramming language kernel. Another amenity is the documentation’s superior formatting in Markdown language and having code snippets called “cells” by which only selected parts of the notebook can be executed and debugged at a time (instead of running the entire notebook over and over and wasting your time). Once you get into the notebooks and start tweaking your code, you will realize that a notebook is not just an expanded documentation, but it is a truly interactive programming environment. Need to take a quick look at your dataframe? One line of code and hit Shift and Enter and it will appear right under your cell. No extra popup windows required. The beauty of creating code cells is that you do not need to re-run the entire notebook if you make a small change and wan to see the outcome. To be clear, Jupyter Notebooks are not only necessary and useful for XEEK or Kaggle work, but are also the every day environment for Data Scientists. Jupyter notebooks are used for prototyping of ML models. However, for deployment, the code is typically written in a .py file or translated into Java Script with less eye-candy. GitHub is a social integration of the git-versioning software. Think of it as the Facebook of programmers where a lot of open source projects are hosted with for collaborative coding and distribution. The central hosting and versioning aspect of it helps groups of programmers to share their code contributions in project repositories (“repos”) and manage and merge updates without having to keep track who now got the latest version of the files on their hard drive. Visitors can “fork” the repository (i.e., taking a copy) and modify the contents after their own liking. Source: https://myoctocat.com/ Before getting started, I recommend reading through the rules and regulations on the contest. Find out what you can do with the data and how your solution will be treated, what rights the competitor has, and what is legally required of the participant to succeed. Read the Rules! . Next step is downloading the competition’s starter notebook and the accompanying .csv files, which contain the actual data. In the starter notebook XEEK used a “Gradient Boosting” algorithm utilizing multiple decision trees. Gradient Boosting is a specific machine learning algorithm that in each stage of regression fits trees on the negative gradient of the binomial or multinomial deviance loss function. This is an interesting choice, since it is a complex algorithm harder to understand, for example than the Support Vector Machine with its hyperspace used to separate different classes. The Gradient Boosting example with all default values yielded a precision of 0.788772 on the Validation Set, which you now got to beat. Your actual score will be published on the website when you make predictions on the Test Set. But you do not have the ground truth answers for the Test Set to score your own model yourself. The XEEK administrators will compare your Test Set predictions against the secret ground truth and publish your result on the contest’s scoreboard website. The data set available for the contest includes thousands of wells all containing exactly 1,100 measurements each (no indications of sampling resolution) does not sound like something you would necessarily get in the real world and seems somewhat synthetic. The starter notebook contains already some exploration including a procedure for smoothing, and splitting off a chunk of the original Train Set as Validation Set. The whole proceedure to step through will look like this: Train a model on Train Set (100,000 samples) Predict on Validation Set (100,000 samples, score optimized for generalization) Predict on on Test Set, save to .csv, send to XEEK (385,000 samples, scored by XEEK) The task at hand is a classification problem where the algorithm is learning to associate measured gamma ray values (the input X) to their assigned geometriy classes (the Y output), which tell the expert the facies and hence hydrocarbon reservoir potential. Here, the challenge is matching a pre-defined class label to gamma ray data. Since there are already labels for the gamma ray data available, we can use supervised learning algorithms. That means the selected algorithm will look for similarities in the labels and during inference use the model to match unlabeled data. If you are not yet that comfortable with Machine Learning algorithms, I can recommend this course, which can be audited for free and delivers deeper insights into the mathematical background than many other courses on the market. After getting more insight in the basics of the algorithms, you may want to get deeper into popular Python libraries such as Sci-Kit Learn, XGBoost, or Keras. All of them come with great documentation and examples. No need to re-invent the wheel. You’re back from the books? Splendid! Now you should have a better grasp on the concept of “training a model”, “generalization”, and “overfitting”. Those are the most important concepts you need for starters on the ML journey. A big question is which algorithm will perform best with what kind of data and how to tune its hyperparameters. All these choices, knobs, and buttons seem a little bit like black magic and requires a lot of experience. However, it is something that can be learned and exercised with a systematic approache plugging in different values in a random search or grid search! Alas, grid search is somewhat a brute force method and requires a powerful computer (multithreading and high core count is king). I wanted some more information in the beginning to find the best algorithm to do the job. At that point I did not know about the importance of feature engineering yet. The most used algorithms in this challenge are: Most Data Science articles talking about “winning Kaggle competitions” will point out that an ensemble method will most likely outperform other methods. Furthermore, it is commonly accepted that the best results are achieved through “Feature Engineering”. A “feature” in the context of ML is something like a column of data. As is, the data is not best conditioned yet for a competitive result. Smart feature engineering can make all the difference and provide large accuracy gains. Machine Learning algorithms are only as good as the data fed to them. The saying that comes to mind is “garbage in, garbage out” or for short GIGO. Feature Engineering augments the original data and means making the data easier readable for the algorithm, which is supposed to improve model accuracy. This may be achieved by combining multiple features mathematically, or modifying a feature. In the starter notebook, the gamma ray data was smoothed in order to get rid of noise, and multiple new feature columns were created for each sample. As stated above, it is very useful to practice and hone your skills. It is paramount to go beyond course material and try yourself. While doing so, it is always important to see how other, more experienced people have tackled a certain problem and take the approach into the own repertoire. It is imprtant to build up a portfolio of projects and keeping at it. I myself have not submitted a notebook in time, having seen the call too late. Nevertheless, only because the prizes and fame are gone, there is no reason not to take the challenge. My current Validaton Set accuracy is not near the top ten on the score board and I believe I have to step up my Feature Engineering game to make some substantial progress Link to Notebook. This entire exercise is iterative and I will keep at it. And you should too. This brief introductiction should cover some basics to participate in the future geo-ML challenges, grow intellectually, and only perhaps make it amongst the top three. Keep at it! Thanks to Michael Lis for giving me pointers to the competition and giveing me helpful advice. Competition Website https://www.xstarter.xyz/ Articles on new Developments in Data Science and Machine Learning https://towardsdatascience.com/ Anaconda Programming Environment https://www.anaconda.com/ Coursera/Stanford University Machine Learning Course by Dr. Andrew Ng https://www.coursera.org/learn/machine-learning Identify objects in your images with computer vision algorithm YOLO. You only look once (YOLO, empahsis on once) is an object detection system using Convolutional Neural Networks (CNN) targeted for real-time processing of camera feeds of all sorts. YOLO is faster than previous algorithm since it does two steps in one. The algorithm divides the image into tiles (e.g. 13x13) and runs the inference for object bounding boxes and object classification on all image tiles simultaneously through the CNN. For example, self-driving cars heavily rely on reliable and fast algorithms, since they need to identify other cars on the street with a camera mounted in the grille. YOLOv2 can be run repeatedly over the input of a camera (30 frames/s) but can make inferences at a speed of 40 times/s! A total of 80 classes are detected in YOLOv2. Only recently YOLO9000 was trained using transfer learning from ImageNet to detect >9000 classes! Prediction on stock photos: Source: Photos from https://unsplash.com/, with own inferences. As you see in the video above, YOLOv2 is not perfect at all yet. Many objects were misclassified, or were not seen because they were too small, or were no class in the first place. But how does YOLOv2 work in detail? The input image is divided into nH x nW grid (for example 13×13 in the architectureal diagram). Each grid cell predicts a fixed number of anchor boxes and confidence scores for those anchor boxes. Each anchor box consists of 5 predictions bx, by, bw, bh and pc (bx,by coordinates of box center; bw, bh lengths of box dimensions, pc confidence) added to the number of classes. The confidence pc here is only for binary classification that those bounding box contains an object or not. With m being the number of input images, the encoded output vector looks the following: (m, nH, nW, anchors, classes), in the case of YOLOv2 that is (m, 13, 13, 5, 85) tensor. Source: Modified after https://unsplash.com/ The architecture of the YOLOv2 CNN is typical for most CNNs, where the height and width of the image shrinks through un-padded convolutions, but get deeper through increasing filers: Source: Seong et al., 2019 The image is resized to 416×416 pixels for training and run through numerous convolutional layers of which many are 1x1 in size to reduce the number of parameters (computational complexity). YOLOv2 removed the 2 fully connected layers and uses anchor boxes to predict bounding boxes. In inference phase, the YOLOv2 algorithm can output multiple bounding boxes for the same object in adjacent tiles and non-max suppression is a technique to resolve it. What non-max suppression do is to keep only the bounding box having maximum confidence score among all boxes that have same classification and have an IoU value (Intersect over Union) >0.5. All boxes that do not meet criteria are eliminated, only the remaining bounding boxes will be displayed. Source: Modified after https://unsplash.com/ If you wanted to run YOLO, that will not be that easy, since it was originally implemented in C language with a neural network framework called Darknet. Running it in Python and Keras does not require you to do the conversion work yourself. Multiple projects have already done that conversion work for you: for example Allan Zelener - YAD2K: Yet Another Darknet 2 Keras. However, I encourage you to try out the deeplearning.ai implementation. Download the contents of this folder. Copy your images for inference into the folder “images”. Make sure all images are exactly 1280x720 resolution. Read through the notebook and runn all cells and look into the “out” folder what your computer’s vision is. YOLO was trained on for some epochs on the pre-trained ImageNet using high-power GPUs. Hence, it is not recommendable to train it yourself. Be advised to download the pre-trained values to make inferences only! The algorithm is continuously optimized by various computer scientists. For example the new iteration YOLO9000, which vastly inceased the number of classes. Have a read of the links given below on how the different versions of YOLO stack up against other computer vision neural networks. Prediction on video feed: Source: Sik-Ho Tsang 2018 Jupyter Notebook deeplearning.ai Jonathan Hui 2018: Real-time Object Detection with YOLO, YOLOv2 and now YOLOv3 Sik-Ho Tsang 2018 Review: YOLOv2 & YOLO9000 — You Only Look Once (Object Detection) Regardless of your skill level, you can only benefit. Photo Credit: TAMU Datathon organizers. In the last couple of weeks, I attended two Hackathons and one Datathon. I recieved a lot of feedback on my endeavours and I want to share my experience with you. As an aspiring Data Scientist, you may have heard of such events and may be curious what they are all about. First off, they are both very similar and present you with different tasks. They are usually hosted by university departments and organized by their students for other students. They are typically held on weekends in Spring and Fall and run for exactly 24 hours from Saturday morning till the same time on Sunday. Hackathon events have now been around for about ten years and often times incorporate Data Science and Machine Learning aspects. But within the last year a new type of -thon was created focusing specifically on Data Science challenges: the DATAthon. Google Trends for search term “datathon”. Takeoff in 2017. Google Trends for event “Hackathon”. Takeoff in 2010. First of all, you should not think that you HAVE to win this competition and need to be an expert to be even considered when you apply for it. Especially if it is your first time. All backgrounds and experience levels are accepted and will be present, from first semester Bachelor’s level to last year PhD. You will benefit a lot in any case, just make the jump. As an (aspiring) Data Scientist you have likely have diverse backgrounds but not necessarily pure coding experience as many Computer Science majors may have. But that is not an issue, since many challenges will require specialists that know the types of data very intimately. And someone needs to know how to interpret the input and what questions to ask! You can form a team with people who complement your knowledge. In order to prepare: Photo Credit: TAMU Datathon organizers Hackathons have relatively open-ended tasks and give you a lot of freedom to what exactly you solve. Hackathon problems will require your creativity to create a solution. This means you have to be cognizant of problems society and individuals may have and an idea how to solve them with technology and software. However, Datathon and Data Science challenges are different. Often times sponsoring companies will contribute with their own data sets that pertain to their everyday business. Find out which companies are participating and you can estimate what kind of problems they want you to solve. For example, if a company that works with business contracts and a lot of text in general, then you might expect a Natural Language Processing challenge. Or an engineering company might present a problem involving predictive maintenance, and data received from IoT sensors. In any case, all challenges are hard enough that you will have time for only a single one. So choose wisely! Hackathons and Datathons allow you to form teams of up to four members. Few participants will work alone and teamwork helps to train your organizational skills, work division, and communication. Make use of this opportunity and communicate with other participants in advance. If you already have someone for your team – good. If not, don’t worry either. You will have chances to find team members on the day of the event, between registration and the start of hacking. However, if you have formed your team in advance, it will save you time on the competition day that you may want to use for actual work. Commonly the organizers will set up a Slack channel where members can communicate starting right after acceptance into the event. Make use of this opportunity and find a team balanced in experience and speciality. Photo Credit: TAMU Datathon organizers I reiterate: It does not matter how much or how little experience you have. You will learn new things regardless and you will be a worthwhile addition to your team. Joining a team that does NOT do what you already know will actually be an opportunity to expand your horizon. If you are not enrolled in a newly minted Data Science program at a university and are starting out from zero, I can recommend the following: When judging time comes, your team will have to present their project to a judge from the hosting university and sometimes professional mentors. You will have 4-5 minutes to present what you did. Summarize what the business question your project tackled and why it is relevant. Why is your solution innovative and how does it benefit the organization? Learn how to make effective (Powerpoint) slides and sum up a project without getting bogged down in details. Judges may be less interested in the exact technical details, but will focus on results and interpretation. It is likely that the organizers will announce on the event website/slack what the exact judging criteria are. Discuss which team member presents what and communicate confidently. Now graphing skills will come in handy because they are distilling your findings into something easy to grasp. If your team did not succeed in finishing the project, that is okay. Explain what your approaches were, how far you got, and what you found challenging. Photo Credit: Christian Haller The Data Science subject is by no means exclusively tractable for Computer Science majors, and actually requires people with domain knowledge to pose the right questions and interpret data. That is true for your team as well. A Hackathon or Datathon is a chance to learn, enrich yourself with this new skillset, and learn new approaches. You do not have to be an expert to have your application approved. A Hackathon or Datathon may just be your way to embark on the journey towards Data Science. If you have more questions, feel free to send me an E-Mail or message on LinkedIn. 360° X-Ray Shots reveal Interior Volumes The MicroCT housed at the Steinmann Institut für Geowissenschaften can scan specimens from large to small (think Brachiosaur skull and friends). With a lower resolution limit of 2 micrometers, it is possible to get satisfactory details on microfossils, such as foraminifera in the size range 1-2 millimeters. The Langer Lab deviced a new mounting technique to successfuly scan foraminifera and reconstruct digital 3D models from tomography images. Goal is measuring structures and volumes of foraminiferal shells without destroying precious specimens. In the figure above the yellow cylinder on the right hand side is the X-Ray source. The specimen is mounted in the hollow plastic cone (pipette tip) directly in front of the opening of the source. The single foraminifera (~1 millimeter) is too small to be seen from this distance. Recorded are the images on a CCD sensor on the left (not pictured) similar to the device in a digital camera, but much larger. The specimen is rotaded 360 degrees in front of the source and images taken at each degree. After the recording is finished, the computer will calculate a black-and-white image stack that is imported into a modeling suite (“reconstruction”). The 3D model can be manipulated and specific materials and volumes marked and measured (see linked materials below). Könen & Langer 2016 Neural Networks can be used to effectifely classify images - unless… Image classification is nowadays a common job for neural networks. The RGB values of a photo are unrolled into a feature vector and the neurons will learn the label given to it. Cat photos are an all-time favorite. Can the computer learn how to distinguish cat photos from non-cat photos? While the Neural Network had a Train Accuracy of 0.986 and a Test Accuracy of 0.8, this does not the trained network will make perfect perfect predictions. Especially the test accuracy is very high high that means that the Neural Network most overfit to the Training Set (i.e., learns it too well), which compromises accuracy for the Test Set. Most likely a regularization technique would have prevented some overfitting and adding training data would be another way. In the meantime, I have to live with the fact that my computer thinks I am a cat. You are invited to download the Jupyter Notebook and run it with you own photo. Let me know what happens. Jupyter Notebook Complex statistical modeling made easy in Python. A Python Machine Learning project for a small geological dataset. This is a project working out how to model reservoir rock permeability from microscope (thin section) images and make predictions. The typical workflow for a new dataset is explained. However, the public data set is very small and thus it is not easy to obtain good prediction scores. I encourage you to take a look into the Jupyter notebooks and run the routines yourself and let me know if you got better results! This project was developed together with BP Reservoir Permeability – Measurements on rock samples for rock permeability Consider making use of your GPU for massive efficiency gains. When analyzing large data sets and building machine learning models, you will inevitably come across the question of how you want to write your code and then where to execute it. This is an especially important question when you are starting out with your endeavors and learning how the modeling is all done nowadays. Computational power is not part of that question and neither that important for toy examples. A lot of training classes will funnel you directly into their online platforms, touting free access and fully managed backends. This takes a lot of work off your hands that you would otherwise have to commit to setting up the environment, curating libraries, worrying about compatibilities etc. Great! Nevertheless, when you start using Neural Networks, you may want to give your own workstation a shot at crunching the numbers. It may pay off. For comparison, I ran the same Jupyter notebook with a Keras sequential model once on IBM Cloud Watson Studio (free tier) and once on the workstation under my desk. The data set is the IMDB sentiment analysis provided pre-processed by Keras and is of moderate size. Here is what I experienced: e.g. IBM Watson Studio, AWS SageMaker Cons Pros The GPU takes 5 milliseconds per step and 119 seconds (~2 minutes) per epoch. This adds up to 1,785 seconds or ~30 minutes for the training process. Cons Pros Neural Networks are calculation intensive tasks that can take hours to days to train depending on the number of samples and model design. The example above indicates that your training can be expedited by many hours (57x faster) by running it on your GPU. The saved time more than compensates for the time spend in setting up Python on your workstation. Even older GPU models by Nvidia will do great and do not require the investment in an RTX 3090 or professional grade board. Free tiers of online platforms such as IBM Watson Studio provide you with CPU power that does not harness the power of GPUs, resulting in long processing times. Of course, if you invest in a higher tier, that may be alleviated with more CPU cores. Or you may directly migrate your code to an advanced library that can address an Apache Spark Cluster, which can deal with industrial-scale amounts of data. But that may be beyond your scope. Meanwhile, your small workstation will save you a lot of time. Spatial analysis and clustering in Python. Shopping malls in the U.S. have received their greatest popularity in the 1970s and 1980s in the and since then investment has stagnated. Numbers of shopping malls exploded beyond the sustainable in many cities. Additionally, today’s brick-and-mortar businesses face the online competition. Despite that many brands meanwhile have successful online stores; the companies wish to remain physically present in their customer’s memory daily life. Despite such a difficult situation, how does the market look like if we use publicly available data and a little bit of number crunching?……. Keep on reading on the link below. Jupyter Notebook Nummulites are the not-so-micro microfossils. Nummulites are a branch of the foraminifera that grow very large. Unlike other genera that can be on the order of 100 μm, these foraminifera grow >1 cm in diameter and are easy to spot with the naked eye. Nummulite fossils are a common occurence in Paleogene carbonate rocks in the Arabic Peninsula, and Mediterranean (“nummulitic limestone”). Hence, it is no surprise that the ancient Greeks, such as the historian Herododuts (5th century BC), had their ideas but no understanding that they were fossilized single-celled marine organisms. Since the flat, round shape of the Nummulite test closely resembles coins, it was a short line of thought to make the connection. In fact, the word “Nummulites” is the diminutive form of the Latin nummulus meaning “little coin”. However, the hand pieces depicted above and below have a different story to tell. The rock is Egyptian limestone that stems from a quarry from where the ancient Egyptian Pharaohs mined rocks for their pyramids. The same limestone - chock full of nummulites - was also used for the construction of the Great Pyramids. Herodotus visited the Great Pyramids and documented what he saw. His conclusion was that they were petrified lentils dropped by the laborers who built the pyramids. So if you have a lentil soup in your garden, please clean up after yourself so that the scientists of the future have it easier and can cross out at least one hypothesis. It is common that nummulite tests will split in half along the long axis so that all the chambers and complex chamberlets become visible (see in figure above). If you have an intact nummulite test and want to split in half as on the photo above, you can try the following: If you are lucky, there will be some differential expansion and the test will come apart smoothly. Getting started with the XEEK Machine Learning contest
Introduction
The Basic Tools
Jupyter Notebooks
![]()
“Git” ready with GitHub

The Contest
Machine Learning

Trying out algorithms
Feature Engineering
Why would anyone want to participate in a competition after it was completed?
Further Reading
Neural Networks for object detection and classification
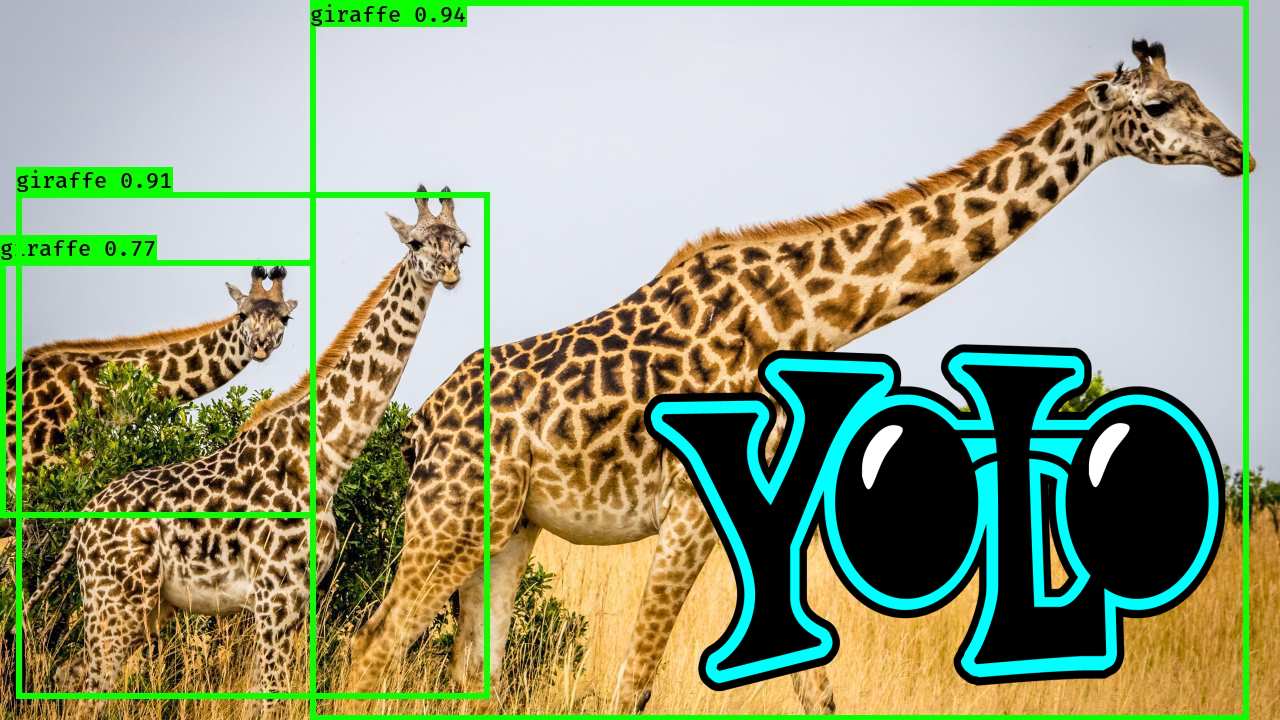
Introduction

How it works
1. Intuition

2. Network Design
3. Non-Max Suppression

Outlook

Further Reading
How to be successful at Hackathons and Datathons for Data Scientists

Introduction
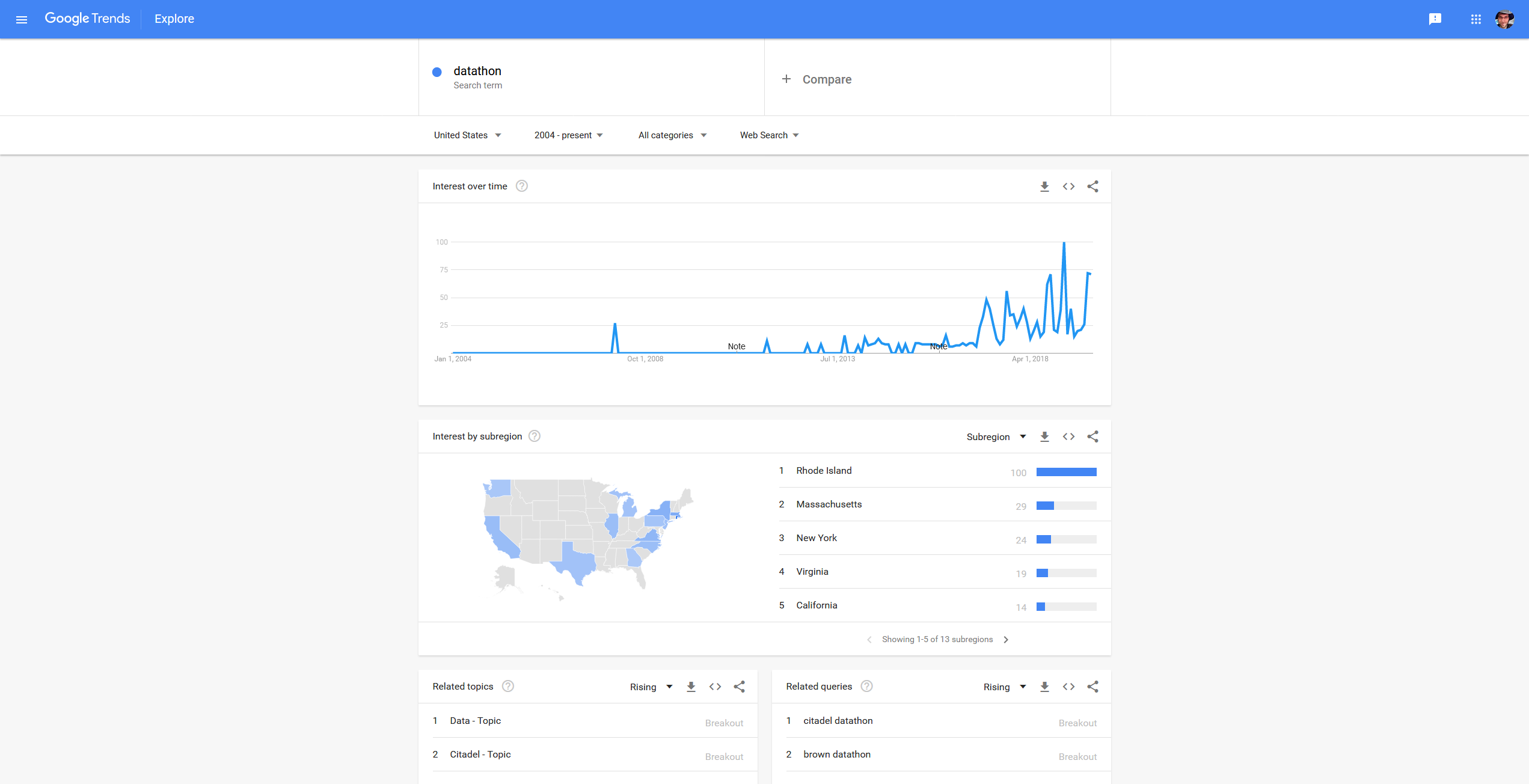
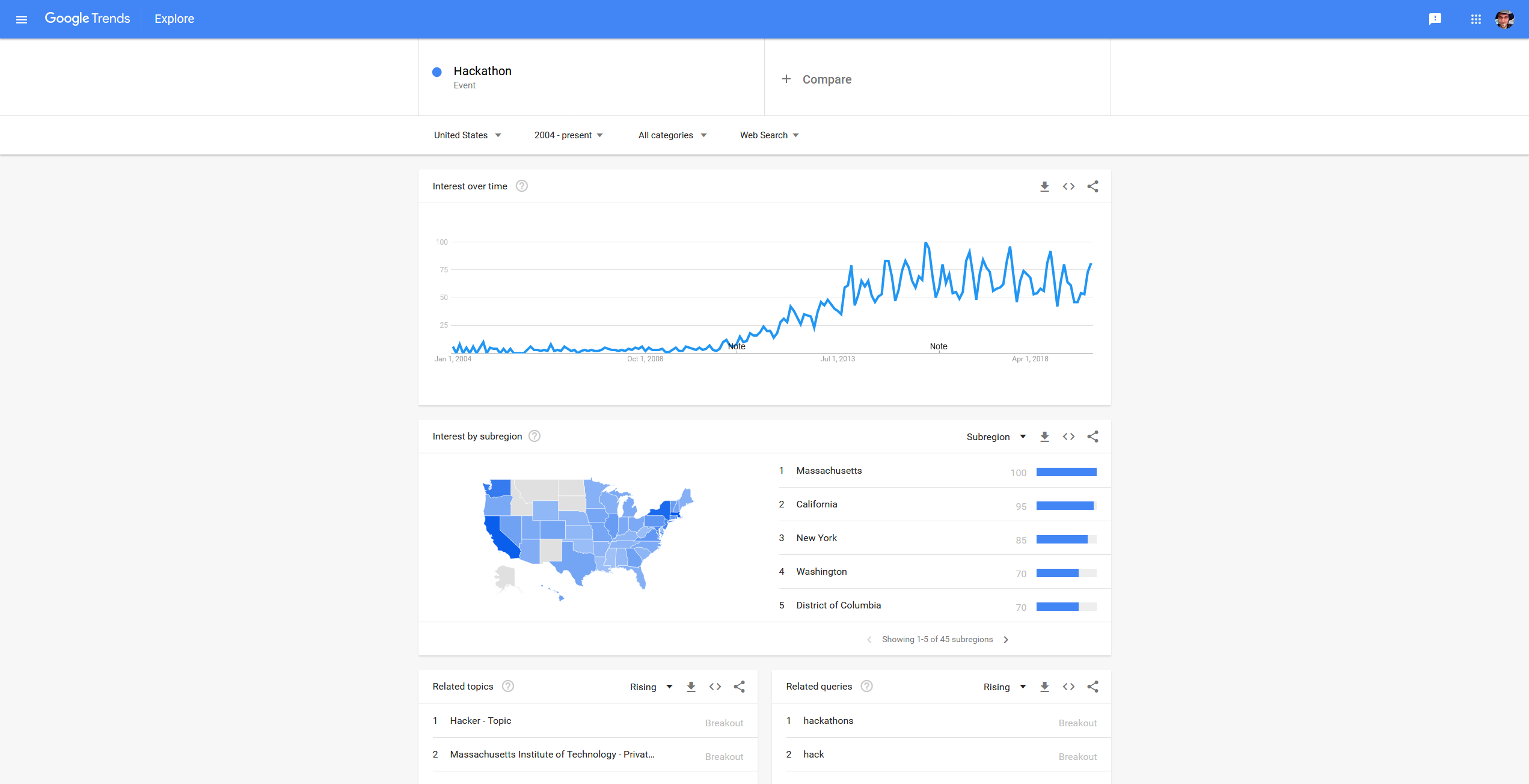
Approach

Types of Challenges
Teams

Technical Knowledge
Presentation

Summary
Hackathons are a great place to learn and get your feet wet. Microfossil Modeling with MicroCT

Introduction

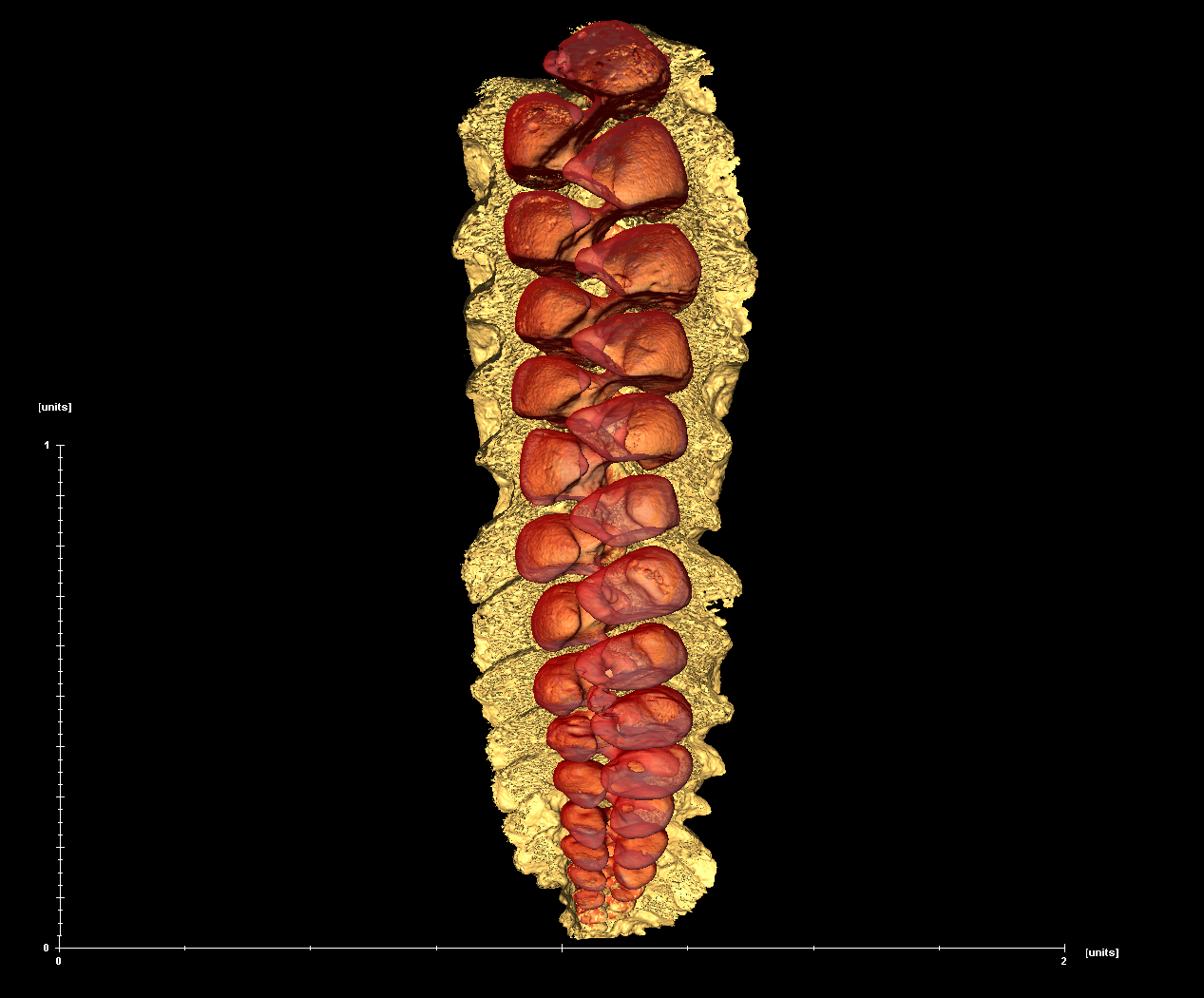
Videos
ResearchGate
Cat Prediction
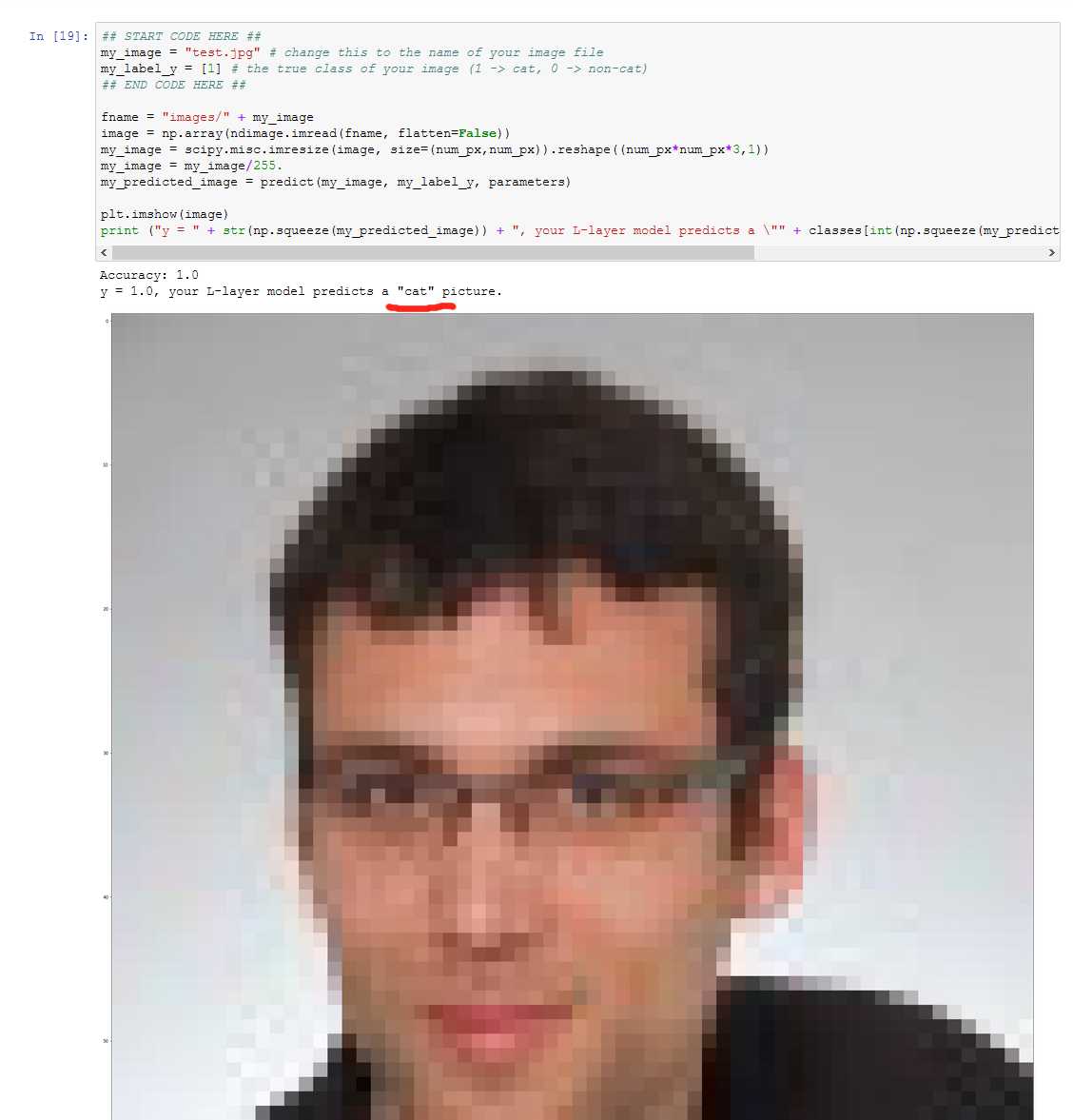
Introduction

GitHub
Rock Permeability Prediction (Data Science)

Introduction
Advanced Data Science with IBM on Coursera.Video
GitHub Repository
Don’t wait for hours (when Deep Learning training)

Introduction

Cloud-based Instance
Workstation with GPU (single node)
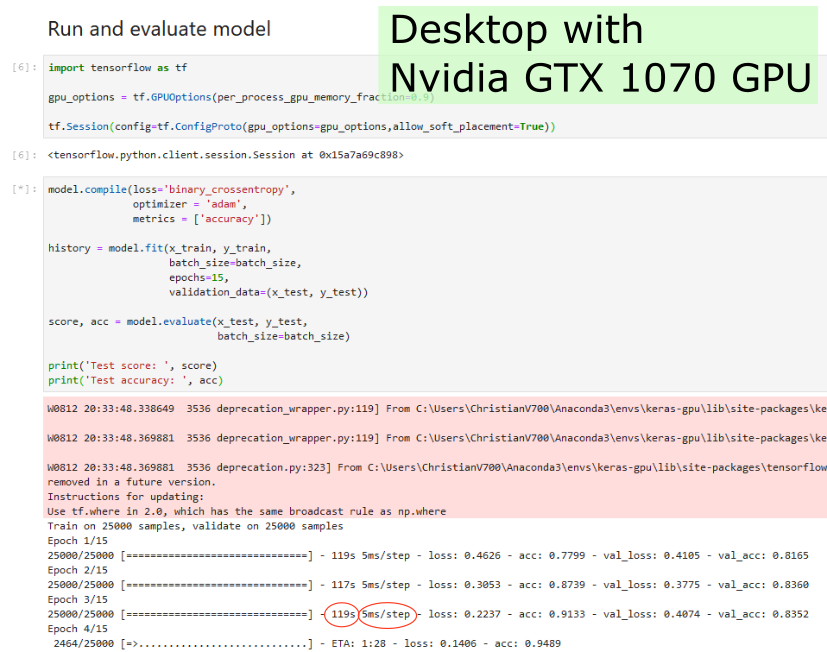
Conclusion
Shopping Mall distribution and possible future development in Charlotte, North Carolina, U.S.A. (Data Science)
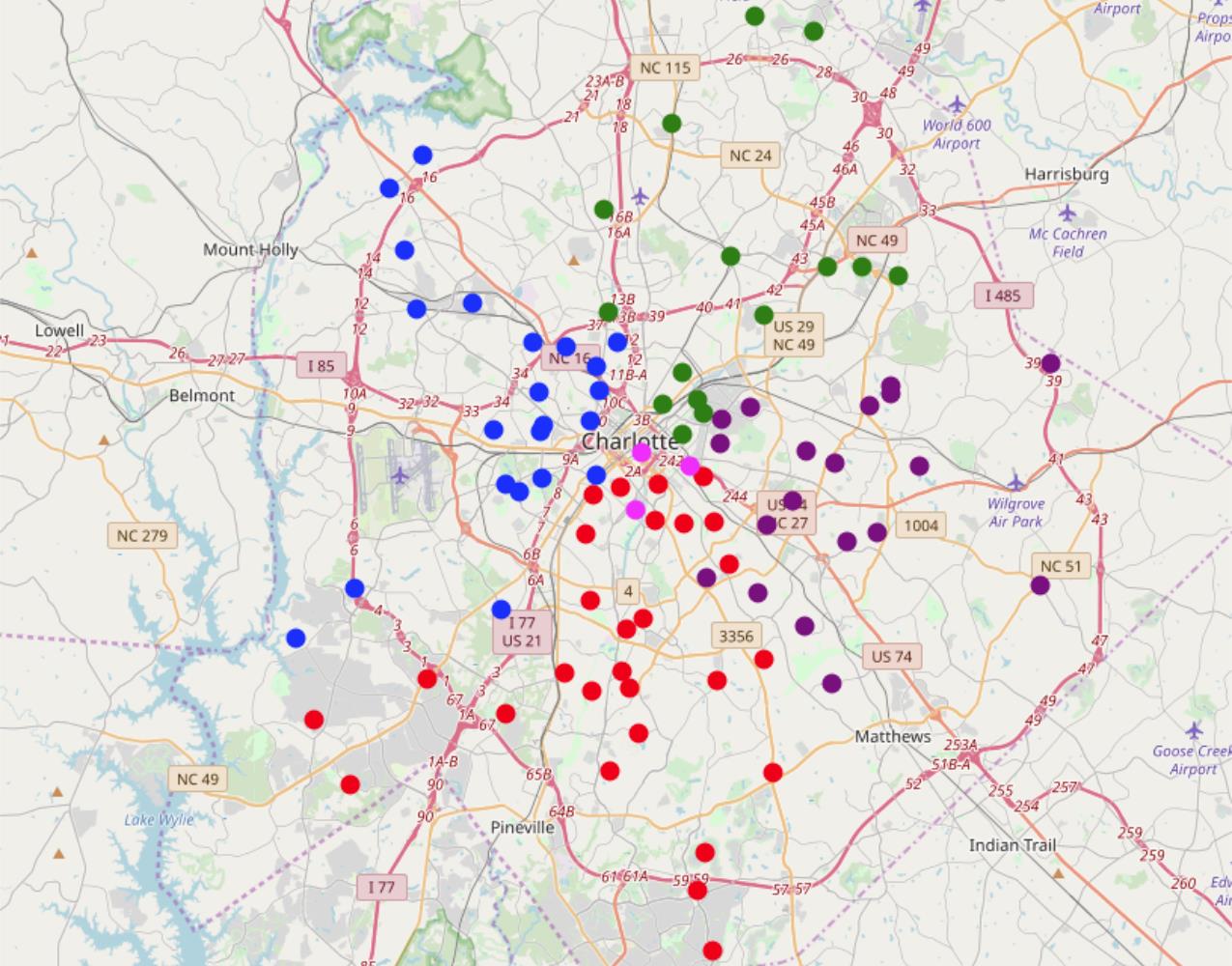
Introduction
Article on LinkedIn
GitHub
Waiter, there is a fossil in my soup...



Pagination